ARPANET - Начало Интернет

Рис. 1.1. Спутник I.
Агентство ARPA (Advanced Research Projects Agency - Агентство перспективных исследовательских проектов) было создано в 1957 г. в ответ на успешный запуск Советским Союзом первого искусственного спутника Земли. Финансируемое Министерством обороны Агентство объединило человеческие ресурсы, которые понадобились для первого американского искусственного спутника - успешный запуск его состоялся 18 месяцев спустя. Однако в 1962 г. задачи ARPA были расширены, чтобы охватить использование компьютеров в военных технологиях, значительная часть которых имела отношение к коммуникации компьютеров и работе сетей.
Постоянной проблемой при проведении исследований и разработок является объединение интеллектуальных ресурсов, необходимых для работы над проблемами или для использования имеющихся возможностей. Достаточно часто специалисты разбросаны географически, что затрудняет обеспечение взаимодействия между участниками или непрерывность развития проектов. Поэтому электронные коммуникации считались важной областью исследований при поддержке рабочих усилий ARPA.
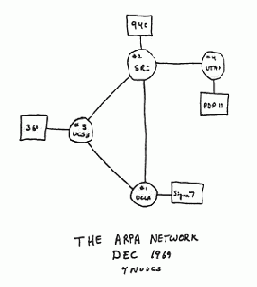
Рис. 1.2. Начальная схема сети ARPANET
Холодная война породила, кроме того, тревогу по поводу воздействия, которое ядерные взрывы могли бы оказать на целостность компьютерных сетей, обеспечивающих военное командование и управление. Было неприятно думать, что даже незначительный перерыв в работе мог бы нарушить военное управление, не говоря уже о разрушениях самой ядерной войны. Поэтому необходимость обеспечения кооперации исследований ученых и инженеров вместе с озабоченностью уязвимостью сети привели к концепции распределенной коммутации пакетов как предпочтительной модели компьютерных коммуникаций.
В этой модели сетевые передачи разбиваются на маленькие пакеты, которые могут перемещаться к месту своего назначения в сети различными путями через различные узлы, через различные компьютеры. Компьютеры передают пакеты данных друг другу различными путями, а компьютер-получатель в месте назначения собирает все пакеты и вновь формирует из них исходное сообщение. При передаче различных частей сообщения различными путями безопасность коммуникации повышается. Также, поскольку пакет может перемещаться различными путями к месту своего назначения, при отказе одного маршрута можно использовать другой. Поэтому распределенная сеть взаимосвязанных компьютеров более защищена и может лучше противостоять разрушениям большого масштаба, чем централизованная сеть, соединенная с одним или несколькими компьютерами-хостами.
В 1969 г. Министерство обороны одобрило проект ARPANET для исследований в области сетей. Первый узел был создан в Университете Калифорнии в Лос-Анджелесе (UCLA), а вскоре были созданы узлы в Станфордском исследовательском институте, в Университете Калифорнии в Санта-Барбаре и в Университете штата Юта. К 1972 г. большая часть работы по разработке оборудования, программного обеспечения и коммуникационных протоколов была перенесена в университеты и исследовательские лаборатории. В 1973 г. сеть ARPANET объединяла 40 машин и имела международные соединения с Великобританией и Норвегией.

Рис. 1.3. Профессор Леонард Клейнрок
Профессор Леонард Клейнрок, известный как один из изобретателей технологии Интернет, создал базовые принципы пакетной коммутации, будучи аспирантом Массачусетского института технологии (MIT). Это было за десять лет до рождения Интернет, которое произошло, когда хост-компьютер Клейнрока в UCLA стал первым узлом Интернет в сентябре 1969 г. Он написал по этой теме первую статью и опубликовал первую книгу; он также управлял передачей первого сообщения, прошедшего через Интернет.
Одной из проблем компьютерных коммуникаций является достоверность сообщений, посылаемых из одного компьютера в другой. Вполне возможно, что компьютеры разных марок и моделей используют и различные методы для отправки и получения пакетов электронной информации. Существует также проблема потерянных пакетов, когда информация не достигает компьютера места назначения в связи с проблемами передачи. Эти вопросы привели к разработке TCP (Transmission Control Protocol - Протокол управления передачей) для обеспечения надежных соединений между различными правительственными, военными и образовательными сетями. Параллельная разработка IP (Internet Protocal - протокол Интернет) решала проблемы сборки пакетов данных и обеспечивала перемещение пакетов в требуемое место назначения.
К 1982 было решено, что сеть ARPANET должна строиться на основе набора протоколов TCP/IP. В этом случае обеспечивалась прямая коммуникация между компьютерами различных сетей с помощью проводных линий связи, радио и спутников. В это время "интернет" стал обозначать соединенное множество сетей, в частности сетей, соединенных с помощью TCP/IP. В тот же год были созданы спецификации EGP (External Gateway Protocol - протокол внешнего шлюза), с помощью которого между собой общались различные сети. В 1984 г. в сети ARPANET было более 1000 компьютеров, и были введены серверы имен доменов (DNS), которые позволяли использовать имена хостов (например, "www.cox.net"), кроме числовых IP-адресов (68.1.17.9), для идентификации и соединения компьютеров в сетях.
Доступ к документам Web
Пользователи взаимодействуют с WWW с помощью программы браузера Web. Чтобы извлечь страницу Web, расположенную на определенном сервере, используется специальная адресация для идентификации сервера и страницы. Этот адрес Web, называемый Единообразным локатором ресурса (URL - Uniform Resource Locator), вводится в адресное поле браузера и посылается через Интернет в поисках сервера.
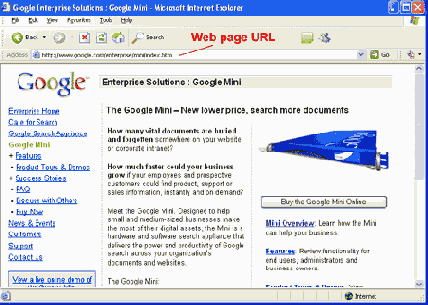
Рис. 1.7. Адрес URL страницы Web
Например, адресом URL страницы, показанной на рисунке 1.7, будет http://www.google.com/enterprise/mini/index.html
URL состоит из нескольких частей:
протокол Часть адреса "http" определяет метод сетевой передачи (протокол), используемый для поиска и доставки страницы браузеру. HTTP является протоколом передачи гипертекста (HyperText Transfer Protocol), стандартным методом, который применяется для взаимодействия с WWW.
имя домена Часть адреса www.google.com определяет имя сервера. Практически всем серверам Web присвоены имена доменов для уникальной идентификации среди всех серверов в Интернет. При отсутствии имени, местонахождение сервера можно определить по его числовому адресу протокола Интернет (IP), записанному в формате с точками 000.000.000.000. Однако обычно используются имена доменов, так как адреса IP трудно запоминать.
путь доступа После прибытия на сервер необходимо пройти путь доступа к каталогу, чтобы найти определенный документ для извлечения. Cтраница Web на рисунке 1.7 имеет путь доступа enterprise/mini; то есть документ расположен в каталоге mini, который является подкаталогом каталога enterprise.
имя файла Имя файла документа является конечной частью пути доступа. Web страница на рисунке 1.7 с именем index.html расположена в каталоге mini.
Обычно требуется знать точное имя страницы Web, чтобы ее извлечь. Однако, если страница имеет имя index.html, как в примере выше, то она извлекается, даже если имя страницы отсутствует в URL. Имя index.html, а также другие специальные имена, такие, как index.htm, defaul.htm и default.html, означают страницу по умолчанию, которая извлекается, если имя страницы не задано.
Именно поэтому можно извлечь страницу Web из Интернет с помощью простого адреса URL из имени домена (например, http://www.google.com). В главном каталоге Web-cайта имеется страница с одним из этих специальных имен, которая будет извлечена. Эту страницу по умолчанию часто называют домашней страницей сайта.
Использование Интернет
В 1969 г. Интернет начинался с четырех узлов и четырех пользователей. Сегодня, согласно Всемирной книге фактов ЦРУ (CIA World Factbook), во всем мире существует более 600 миллионов пользователей Интернет, что составляет около 9% населения Земли. Однако распространение Интернет не равномерно на земном шаре. Лидируют страны, обладающие высоким интеллектуальным и организационным потенциалом вместе с политической и экономической системами, необходимыми для развития этих возможностей. Страны, занимающие первые двадцать пять позиций по доле пользователей Интернет от общего количества населения, показаны в таблице 1.1.
Таблица 1.1. Распределение пользователей Интернет по странам
ПозицияСтранаПользователиПроцент| Весь мир | 604,111,719 | 9.4 | |
| 1 | Исландия | 195,000 | 65.7 |
| 2 | Тайвань | 13,800,000 | 60.3 |
| 3 | Южная Корея | 29,220,000 | 60.1 |
| 4 | Лихтенштейн | 20,000 | 59.3 |
| 5 | Швеция | 5,125,000 | 56.9 |
| 6 | США | 159,000,000 | 53.8 |
| 7 | Новая Зеландия | 2,110,000 | 52.3 |
| 8 | Сингапур | 2,310,000 | 52.2 |
| 9 | Нидерланды | 8,500,000 | 51.8 |
| 10 | Дания | 2,756,000 | 50.7 |
| 11 | Финляндия | 2,650,000 | 50.7 |
| 12 | Пакистан | 1,500,000 | 50.0 |
| 13 | Норвегия | 2,288,000 | 49.8 |
| 14 | Канада | 16,110,000 | 49.1 |
| 15 | Германия | 39,000,000 | 47.3 |
| 16 | Австралия | 9,472,000 | 47.1 |
| 17 | Гонконг | 3,212,800 | 46.6 |
| 18 | Австрия | 3,730,000 | 45.6 |
| 19 | Япония | 57,200,000 | 44.9 |
| 20 | ОАЭ | 1,110,200 | 43.3 |
| 21 | Великобритания | 25,000,000 | 41.4 |
| 22 | Латвия | 936,000 | 40.9 |
| 23 | Словения | 750,000 | 37.3 |
| 24 | Малайзия | 8,692,100 | 36.3 |
| 25 | Франция | 21,900,000 | 36.1 |
Источник: CIA World Factbook (http://www.odci.gov/cia/publications/factbook/index.html)
Для стран, объединенных по регионам, степень использования Интернет показана в Таблице 1.2. Примечательно то, что Северная Америка и Европа составляют более 52% пользователей Интернет, хотя в абсолютных числах азиатские страны имеют наибольшее число пользователей.
Таблица 1.2. Распределение пользователей Интернет по регионам
ПозицияРегионПользователейПроцент| 1 | Северная Америка | 223,392,807 | 68.0% |
| 2 | Океания/Австралия | 16,448,966 | 49.2% |
| 3 | Европа | 269,036,096 | 36.8% |
| 4 | Латинская Америка | 68,130,804 | 12.5% |
| 5 | Азия | 323,756,956 | 8.9% |
| 6 | Средний Восток | 21,770,700 | 8.3% |
| 7 | Африка | 16,174,600 | 1.8% |
Источник: Internet World Stats (http://www.internetworldstats.com/index.html)
История Интернет и его использования
Всемирная паутина (WWW) широко проникла в современную жизнь. Просмотр страниц Web и использование e-mail стали повседневной деятельностью большинства людей, и кажется, что эти технологии существовали всегда. Конечно, базовая технология Интернет существует уже не менее 40 лет, но паутина Web появилась совсем недавно, ее основное развитие происходило только в последнее десятилетие.
Подобно большинству технологий Web возникла на основе предшествующих разработок, никак не предвещавших конечную форму, которую они могут принять. Технология начиналась с нарождающимся чувством некоторой цели, которая затем навсегда отклонилась в области, никак не предполагавшихся в начале. Историческое развитие этих базовых технологий представляет собой интересный холст, на котором рисуется портрет все еще юной и незрелой Web.
Изучение HTML
Язык HTML не является языком программирования компьютеров. Это просто набор кодов разметки, которые структурируют и задают стиль текста и графики, имеющихся на странице Web. Изучение HTML является, по сути, изучением этих тегов разметки и их использования для задания стиля страниц Web.
Существуют доступные методы для создания страниц Web, не требующие изучения HTML. Это хорошо известные программы Microsoft FrontPage или Macromedia Dreamweaver. Это редакторы страниц Web, работающие в режиме WYSIWYG ("что видим, то имеем") и использующие буксировку элементов, которые неявно для пользователя создают необходимые коды. Фактически можно создавать страницы Web с помощью этих программных пакетов, совершенно не зная HTML. Зачем же тогда беспокоиться об изучении HTML?
Для временного или случайного автора страницы Web, который поддерживает простой персональный Web-сайт, возможно, что знание HTML не требуется. Визуальный редактор со средствами буксировки позволяет создавать и организовывать контент страницы без знания нижележащего кода. Неведение блаженно. Однако умному разработчику, профессионально отвечающему за создание и поддержку коммерческих сайтов, жизненно важно знать язык HTML. Это остается в силе, даже если для создания страниц используются визуальные редакторы. По мере того как приложения Web становятся все более сложными, необходимо иметь возможность разобрать страницы на части и собрать их снова на уровне кода, а не только на уровне контента. Необходимо, в некотором смысле, иметь возможность поднять капот и починить двигатель.
Достаточно часто студенты после изучения кодирования HTML предпочитают работать на уровне кода, а не использовать инструменты WYSIWYG. В этом случае имеется больше возможностей контроля над проектом страницы и достаточно часто оказывается легче работать непосредственно с кодом, чем с программой редактора.
Язык разметки HTML
С самого начала языком разметки для страниц Web был язык разметки гипертекста (HTML). Он действует с помощью специальных команд, которые помещают вокруг текстового и графического контента (информационного содержания), присутствующего на странице. Эти команды инструктируют браузер, как организовать и вывести этот контент. В качестве очень простого примера на листинге 1.1 показана строка кода,
<h2>Форматировать эту строку текста.</h2>
Листинг 1.1. Код HTML для форматирования строки текста (html, txt)
которая окружает текстовую строку "Форматировать эту строку текста." тегами HTML для разметки <h2> и </h2> (стиль заголовка 2), чтобы вывести текст показанным на рисунке 1.10 стилем.
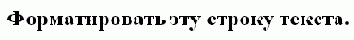
Рис. 1.10. Вывод браузером форматированной строки текста
Эти коды разметки приказывают браузеру форматировать текст, увеличивая и делая жирными появляющиеся между ними символы. Коды разметки, называемые также тегами или элементами HTML, всегда помещаются между символами "<" и ">", чтобы выделить их в текстовом контенте, к которому они применяются. Обычно "открывающий" тег указывает на начальную точку форматирования (<h2> в примере выше), а отдельный "закрывающий" тег указывает на конечную точку форматирования (</h2> в примере выше). Изучив доступные теги HTML, можно создавать свои собственные страницы Web для представления текста и графики практически в любом требуемом виде.
Каскадные таблицы стилей
Теги XHTML являются идентификаторами и контейнерами текстовой и графической информации, выводимой на странице Web. Их основное применение состоит в описании структуры этого содержимого, в упаковке его для размещения на этой странице. Однако большинство страниц Web содержат больше, чем обычный текст и размещенные в нем с помощью тегов XHTML встроенные изображения. Информация на странице имеет дополнительное оформление, делающее ее более привлекательной и легко читаемой. Различные виды шрифта, размер текста, цвет и другие характеристики форматирования делают страницу более удобной для чтения и, при благоразумном использовании, могут сделать информацию более понятной.
В предыдущих версиях HTML большая часть оформления контента страницы происходила с помощью атрибутов, задаваемых как часть ее тегов. Атрибуты определяли дополнительные спецификации форматирования помимо тех, которые подразумевает само имя тега. Например, начертание шрифта можно задавать для текстовой информации, окружая ее тегом <font>, содержащим атрибуты для задания вида шрифта, размера и цвета: <font face="arial", size="4", color="red">. Различные теги содержали различные атрибуты для форматирования своего содержимого различным образом.
В текущих версиях XHTML атрибуты тегов почти исчезли, будучи исключены (исключены в использовании) в пользу каскадных таблиц стилей (CSS - Cascading Style Sheets), или просто кратко "таблиц стилей". Таблица стилей является набором характеристик оформления, связанных с тегами XHTML. Эти характеристики оформления состоят из свойств оформления и значений, записанных с помощью специального синтаксиса таблиц стилей и присвоенных тегам, которые будут наследовать эти стили оформления. Например, одним из способов присвоить таблицу стилей тегу является включение ее в тег в качестве атрибута style.
<p style="font-family:arial; font-size:14pt; color:red; font-weight:bold"> Это текстовый параграф. </p>
Листинг 1.8. Присвоение таблицы стилей параграфу (html, txt)
В этом примере параграфу текста, окруженному тегом <p> (paragraph), задается тип шрифта Arial размером 14pt (14 пунктов), красного цвета (red), с жирной насыщенностью (bold). Четыре спецификации свойство:значение (например, font-family:arial) задают эти стили оформления.
Любому тегу XHTML можно присвоить одну или несколько характеристик оформления, и существуют сотни различных свойств оформления и значений, которые могут использоваться. Большая часть изучения XHTML состоит из изучения этого множества возможностей оформления. Категории стилей оформления включают:
стили шрифта - для задания типа шрифта, размера и насыщенности.;
стили текста - для задания интервала между буквами и словами, высоты строк, горизонтального и вертикального интервала и абзацных отступов;
стили цвета - для задания цвета фона и переднего плана;
стили рамок - для вывода различных рамок, окружающих текстовые и графические элементы;
стили отступов - для задания ширины различных отступов, окружающих текстовые и графические элементы;
стили фильтрации - для применения специальных эффектов к текстовым и графическим элементам;
стили задания размера - для задания высоты и ширины текстовых и графических контейнеров;
стили позиционирования - для позиционирования элементов страницы в фиксированных пиксельных координатах на странице.
Консорциум WWW поддерживает стандарты языка каскадных таблиц стилей, так же, как это делается для языка разметки XHTML. Текущей версией стандартов, рассматриваемой в данном учебнике, является CSS Level 2 (CSS2).
Основная задача при освоении XHTML - изучение тегов и особенностей их стилей оформления, которые применяют форматирование браузера к содержимому страницы, которое они охватывают. Обычно в этом учебнике представлены только те теги и параметры таблицы стилей, которые являются существенными для рассматриваемого вопроса. Дополнительные теги и возможности оформления вводятся по мере изучения материала учебника.
Не имеет значения, что показанные в этом учебнике примеры являются достаточно простыми иллюстрациями тегов и стилей. Цель состоит в том, чтобы продемонстрировать код XHTML и основные подходы к оформлению, а не создать тщательно разработанные демонстрации. В этом случае читатель будет сосредоточен на коде и не будет перегружен большим объемом информационного содержимого. Помните, однако, что можно создавать страницы достаточно сложной структуры, объединяя представленные здесь основные понятия XHTML и элементы таблиц стилей.
Комментарии в XHTML
Для описания различных разделов документа Web желательно помещать в нем комментарии, которые являются общими описаниями или пояснениями кода XHTML. Они служат полезным напоминанием назначения или содержания разделов кода, когда придется через какое-то время вернуться к редактированию документа. В приведенном выше примере в начале раздела <body> был помещен общий комментарий.
<!-- Здесь находится параграф для вывода в браузере -->
Комментарии помещают между парой тегов <!-- и -->. Эти теги могут окаймлять однострочный комментарий, как показано выше, или несколько строк кода XHTML. Любой код или текст, находящийся между этими символами, игнорируется браузером и не выводится на странице.
Кроме размещения примечаний и заметок в документе, теги комментариев можно использовать для временного отключения вывода браузером части кода. Это часто бывает полезно во время "отладки" страницы, то есть во время поиска ошибок с помощью частичного удаления разделов кода, пока проблема не будет изолирована.
Второй способ комментирования небольшого фрагмента кода HTML состоит в использовании в теге восклицательного знака (!). Этот символ можно задействоать для приостановки вывода целого тега - добавляя его в начале тега, - или одного из его атрибутов - добавляя его перед атрибутом. В следующем примере этот символ применяется для удаления форматирования строки текста, комментируя обрамляющий тег <p>.
<!p style="font-family:arial; color="red"> Вывести эту строку красным цветом. <!/p>
Кстати, восклицательный знак не является формальным, утвержденным символом комментария. Можно использовать любой другой символ, так как он просто искажает имя тега или имя атрибута, делая его бессмысленным для браузера. Восклицательный знак применяется здесь просто для совместимости со стандартным тегом комментирования.
Контейнерные и пустые теги
Теги XHTML являются специальными ключевыми словами, окруженными угловыми скобками "<" и ">". "Имена" этих элементов указывают на назначение тега и предписывают браузеру интерпретировать вложенный контент специальным образом. В примере страницы, показанной на листинге 1.6, тег <html> окружает все содержимое страницы и говорит о том, что оно является документом HTML и должно соответствующим образом интерпретироваться браузером. То есть, браузер должен искать теги XHTML и использовать вложенные спецификации разметки для оформления информации, окруженной тегами. Аналогично теги <body> окружают весь контент страницы, которая выводится в окне браузера. В соответствии со стандартами XHTML все ключевые слова записываются символами нижнего регистра. Большинство тегов XHTML кодируются парами из открывающего и закрывающего тегов, называемых контейнерными тегами. Открывающий тег является самим ключевым словом, появляющимся между символами < и >; закрывающий тег имеет такой же формат, в котором перед ключевым словом стоит прямая косая черта (/). Эта пара контейнерных тегов охватывает данные, к которым применяется форматирование. Следовательно, пара контейнерных тегов <html>...</html> окружает весь документ HTML, чтобы указать, что все находящееся между ними кодируется на языке HTML. Таким же образом пара контейнерных тегов <body>...</body> охватывает все содержимое страницы, которое выводится в окне браузера.
Не все теги являются контейнерными, то есть они не "окружают" данные, которые будут форматироваться, а кодируются единственным, автономным тегом. Такие пустые теги кодируются специальным образом, чтобы соответствовать стандартам XHTML. Они должны содержать символ наклонной черты (/) непосредственно перед закрывающей угловой скобкой. Например, одиночный тег для вывода горизонтальной линии на странице кодируется как <hr/>, а одиночный тег для создания разрыва строки в текстовом параграфе - как <br/>. Такое специальное кодирование указывает, что тег служит одновременно открывающим и закрывающим.
Корневой элемент <html>
Наконец, корневым элементом (открывающим тегом) страницы XHTML должен быть тег <html>, указывающий пространство имен применяемого стандарта, то есть, расположение в Web применяемого для страницы стандарта XHTML. Во всех случаях корневой элемент кодируется, как показано на листинге 1.5.
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
Листинг 1.5. Корневой элемент <html> (html, txt)
NSFNET - Развитие Интернет
Развитие того, что стало теперь Интернетом, берет старт в 1986 г., когда началось финансирование Национального научного фонда (NSF - National Science Foundation). Сеть NSFNET была первоначально создана для связи суперкомпьютеров в основных исследовательских организациях, но она быстро выросла и включила в себя большинство крупнейших университетов и исследовательских лабораторий. В 1990 г. существовало более 300000 хост-компьютеров. В 1994 г. по поручению NSF был подготовлен отчет с названием "Осознание информационного будущего: Интернет и дальнейшее развитие". Этот отчет представил программу эволюции "информационной супермагистрали" и оказал значительное влияние на пути развития Интернет.
В 1995 г. после короткой, но успешной истории финансирование NSFNET было прекращено и были сняты ограничения на коммерческое использование, что привело к экспоненциальному росту использования Интернет. Финансирование, которое шло на поддержку NSFNET, было перераспределено между региональными сетями, чтобы помочь им в получении соединения с Интернет у многочисленных новых коммерческих поставщиков сетевых услуг. За следующие три года количество хост-сайтов росло на миллион в год, а в 1995 -1997 гг. число сайтов увеличивалось более чем на 6 миллионов в год и достигло почти 20 миллионов. К этому времени правительственные агентства, образовательные учреждения и частные предприятия стали активными клиентами Интернет.
24 октября 1995 г. Федеральный совет по сетям (Federal Networking Council) единогласно одобрил резолюцию, определяющую термин Интернет (Internet):
Термин "Internet" (Интернет) относится к глобальной информационной системе, которая - (i) логически связана глобально уникальным адресным пространством на основе Протокола Интернет (IP) или его последующими расширениями/ усовершенствованиями; (ii) способна поддерживать коммуникацию с помощью пакета протоколов TCP/IP или его последующими расширениями/ усовершенствованиями, и/или другими, совместимыми с IP протоколами; и (iii) предоставляет, использует или делает доступными, публично или в частном порядке, высокоуровневые службы, опирающиеся на коммуникацию и описанную здесь инфраструктуру.
Интернет можно считать технической инфраструктурой - это компьютеры, кабели, сети и механизмы коммутации, обеспечивающие коммуникацию одного компьютера с другим. Однако, в конечном счете, достоинства сетевых компьютеров оцениваются информацией, которой обмениваются сидящие перед компьютерами люди. E-mail и программы пересылки файлов были с самого начала неотделимы от целей создания Интернет, соединяя людей друг с другом и с нужной им информацией.
Обслуживание страниц Web
Всемирная паутина (WWW) является, как говорит само название, сетью компьютеров мирового масштаба, которая распространяет документы, называемые страницами Web, через обширную "паутину" сетевых соединений. Web является частью Интернет, поэтому обмен страницами может происходить между компьютерами, расположенными в любом месте в мире, где имеется соединение с Интернет.
Пролог
Все документы XHTML должны начинаться со строк пролога, показанных на листинге 1.10. Первая строка говорит, что этот документ основывается на XML версии 1.0. Остальные строки указывают на определение типа документа (DTD), описывающее используемый на странице стандарт кодирования W3C, в данном случае XHTML версии 1.1.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
Листинг 1.10. Пролог страницы Web (html, txt)
Просмотр локальных страниц Web
Кроме получения доступа через Интернет страницы Web можно просматривать локально. Личные страницы Web можно сохранить на своем настольном ПК и открывать в браузере. Эти страницы ничем не отличаются от любых других файлов на компьютере. Фактически все документы Web, описанные в этом учебнике, можно создать на своем настольном ПК, сохранить на своем настольном ПК и извлекать для вывода на своем настольном ПК.

Рис. 1.8. Значок страницы Web
Чтобы открыть локальный документ Web в своем браузере, можно сделать двойной щелчок на значке документа на рабочем столе. В результате автоматически откроется браузер и выведет эту страницу.
Можно также просматривать локальную Web-страницу, открывая сначала браузер и выбирая затем "Open..." (Открыть ... ) из меню File, а затем просмотреть каталоги на диске, чтобы найти и открыть документ. Этот процесс показан на рисунке 1.9.
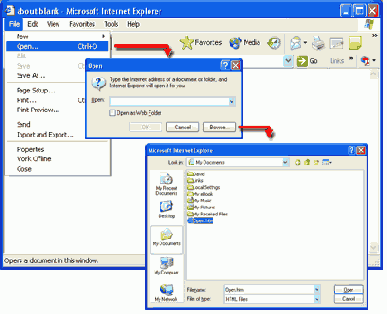
Рис. 1.9. Открытие локальной страницы Web
Работа с документами XHTML
Документы XHTML имеют простую общую структуру, которая формирует основу для создания всех страниц Web. Эта базовая структура тегов показана на следующем листинге с помощью соответствующих тегов, описанных в следующих разделах.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"> <head> <title>здесь находится заголовок страницы</title> </head> <body> . здесь находится содержимое страницы . </body> </html>
Листинг 1.9. Шаблон страницы Web (html, txt)
Создание страницы XHTML можно начинать с этого шаблона. Можно создать этот документ в редакторе и сохранить его как файл шаблона. Затем, при создании новой страницы, откройте просто этот документ, сохраните его под именем новой страницы и продолжайте кодирование в соответствии с той задачей, для которой предназначена новая страница.
Развитие стандартов HTML
Как отмечалось, консорциум WWW (W3C) поддерживает стандарты технологий Интернет, включая стандарты для языков разметки Web. Самый ранний стандарт HTML появился в 1995 г., за ним последовали версии HTML 3.0, HTML 3.2, и завершилась разработка в 1999 г. версией HTML 4.01. Однако в дальнейшем происходит существенная переработка языков разметки.
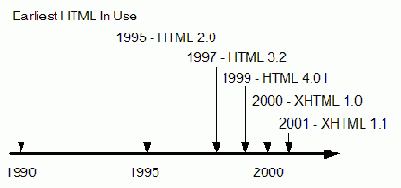
Рис. 1.11. Развитие версий HTML
Последние усилия W3C сосредоточены на определении нового языка XML (eXtensible Markup Language - Расширяемый язык разметки) для использовании в качестве универсального языка разметки, заменяющего более старые языки, и со стандартами создания будущих языков для специальных случаев разметки. Например, были созданы версии XML для генерации графики Web (VML - Vector Markup Language), для вывода математических выражений (MathML - Mathematical Markup Language), для создания интерактивных аудио/видео представлений (SMIL - Synchronized Multimedia Integration Language), для распознавания цифровой подписи (InkML - Ink Markup Language) и другие.
Недавние усилия по переработке HTML как языка на основе XML привели к его текущей инкарнации в качестве XHTML (eXtensible HyperText Markup Language - Расширяемый язык разметки гипертекста). Начальная версия, XHTML 1.0, появилась в 2000 г. как переходный стандарт, который все еще распознает некоторые популярные свойства HTML. Однако к 2001 г. он развился в версию XHTML 1.1 и полностью отказался от оставленных свойств предыдущих стандартов HTML. Язык в настоящее время пересматривается в направлении версии XHTML 2.0.
Различные браузеры пытаются поддерживать стандарты HTML и XHTML, некоторые более успешно, чем другие. Например, для современных версий Internet Explorer или Firefox можно будет без опаски использовать язык XHTML, описанный в этом учебнике.
Редактирование документа и вывод
При создании длинной страницы Web нет необходимости кодировать всю страницу сразу. Можно закодировать несколько строк, сохранить документ, просмотреть страницу в браузере, а затем вернуться к составлению следующего фрагмента кода. Другими словами, можно переключаться между редактором и браузером при составлении страницы Web. Начните просто с описанного ранее шаблона документа, чтобы создать совершенно правильный валидный документ Web.
Чтобы облегчить такую разработку страницы, оставьте окна редактора и браузера открытыми на рабочем столе, где они будут доступны в панели задач. Затем можно делать изменения или исправления в документе и сразу переключаться в браузер, чтобы увидеть обновленную страницу.
Следующая иллюстрация показывает экран компьютера с одновременно открытыми на рабочем столе программами Notepad и Internet Explorer. Теперь очень легко щелкнуть в окне Notepad, чтобы редактировать документ Web. После сохранения изменений щелкните в окне Internet Explorer, а затем нажмите кнопку Refresh, чтобы перезагрузить измененный документ. Затем вернитесь в окно Notepad, чтобы продолжить разработку страницы.
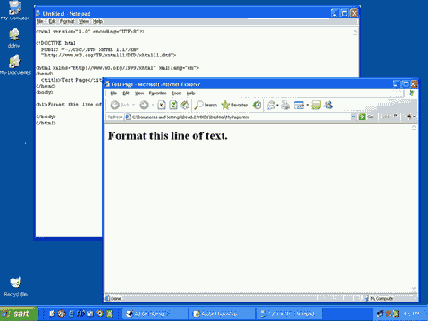
Рис. 1.18. Редактор страницы Web и браузер, открытые на рабочем столе
Между прочим, существует быстрый способ открыть документ Web для редактирования в Notepad при просмотре страницы в окне браузера. В меню браузера View выберите команду Source, что означает просмотр исходного кода страницы XHTML. Страница автоматически откроется в редакторе Notepad, как показано на рисунке 1.19.
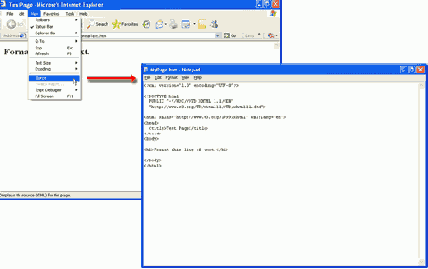
Рис. 1.19. Открытие редактора Notepad из браузера
Редактирование текста с помощью Notepad
Документы XHTML создаются с помощью текстовых редакторов или с помощью специальных редакторов HTML, созданных для этой цели. Для данного учебника достаточно использовать простой текстовый редактор, такой, как Windows Notepad. Эта программа обычно находится в меню Start-->All Programs-->Accessories. После запуска этого редактора можно ввести текст и другие элементы страницы, которые желательно вывести, дополняя тегами XHTML для компоновки и оформления.
Рисунок 1.16 показывает редактор Notepad с кодом простой страницы Web. Эта страница имеет заглавие, которое выводится в панели заглавия браузера, и одно предложение, которое выводится в окне браузера.
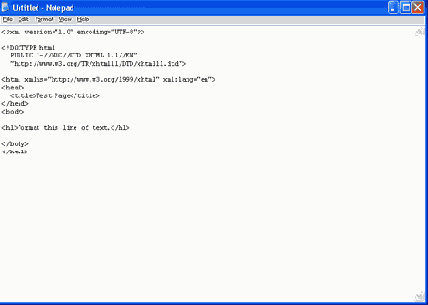
Рис. 1.16. Окно Notepad с кодом XHTML
Текст и кодирование вводятся в редакторе в свободном формате. То есть, пробелы, табуляция, абзацные отступы, и другие средства редактирования документа можно и нужно использовать, чтобы сделать документ в редакторе удобочитаемым. Эта компоновка редактора игнорируется браузером, который обращает внимание только на теги XHTML, определяющие компоновку документа и инструкции форматирования. Приведенный выше код, например, будет выведен в браузере правильно, даже если его ввести в редакторе в следующем виде:
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml11.dtd"><html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"><head><title>Страница Page</title></head><body> <h2>Форматировать эту строку текста.</h2></body></html>
Однако легче составлять и редактировать документ и понимать компоновку страницы, размещая ее теги и текст в более удобочитаемом формате. Уделите большое внимание выравниванию и отступам кода, чтобы визуально он представлял структуру выводимого в браузере контента. Небрежный код неизбежно ведет к ошибкам. Необходимо выбрать для вывода кода в Notepad моноширинный шрифт, такой, как Courier New. Моноширинный шрифт облегчит выравнивание строк текста в редакторе. Кодирование XHTML является трудным искусством и наукой. Аккуратность кодирования - требование первостепенное, здесь нужна работа с точностью, приближающейся к 100%. Браузер не знает, что "хочет" сделать программист; браузер может делать только то, что ему будет точно сказано. Сначала кодирование будет утомительным и трудоемким. Однако после некоторой практики можно научиться вводить и редактировать код XHTML почти так же просто, как обычный текст.
Серверы и клиенты
Существует два типа компьютеров, которые соединяются с Интернет и делают возможным обмен документами. Компьютеры сервера Web являются хранилищами страниц Web. Страница Web должна быть размещена на компьютере сервера, который соединен с Интернет, прежде чем к странице можно будет обратиться. Компьютеры клиентов Web являются настольными ПК, которые соединяются с этими серверами для получения доступа к хранящимися там документам Web. На клиентских ПК выполняется программа браузера Web, осуществляющая загрузку документов с серверов и вывод на экране полученных страниц.

Рис. 1.6. Загрузка Web-страницы с сервера для вывода на ПК клиента
Сохранение документа XHTML
После завершения кодирования документа XHTML необходимо сохранить его, чтобы затем его можно было извлечь и вывести в браузере. Документ можно сохранить на рабочем столе, на сменном устройстве хранения или в папке на жестком диске.
Для документа Web можно выбрать любое имя файла, хотя оно не должно включать никаких пробелов или специальных символов. Документ необходимо также сохранять с расширением файла .htm. Это расширение идентифицирует документ как страницу Web, чтобы браузер мог ее распознать. При использовании в качестве редактора Windows Notepad не забудьте выбрать в качестве типа файла All Files (*.*) из выпадающего меню. Иначе Notepad добавит расширение .txt к имени файла, и документ будет неправильно опознаваться браузером.

Рис. 1.17. Сохранение документа XHTML в Notepad
Сохранение и вывод первой страницы Web
После кодирования страницы сохраните документ, чтобы его можно было вызвать в браузере. Место сохранения документа зависит от рабочей среды. При работе на стандартном настольном ПК сохраните документ на дискете или в папке на жестком диске. Не забудьте также сохранить документ со специальным расширением файла .htm. Сохраните этот конкретный документ с именем FirstPage.htm, или любым другим именем на свое усмотрение.
Теперь откройте браузер и загрузите страницу. Желательно оставить редактор открытым на рабочем столе, так как это будет удобно для внесения исправлений или изменений на странице. Если документ совпадает с вышеприведенным примером, то страница Web должна появиться в окне браузера так, как показано ниже. Эта страница была загружена с локального жесткого диска и выводится в Internet Explorer.
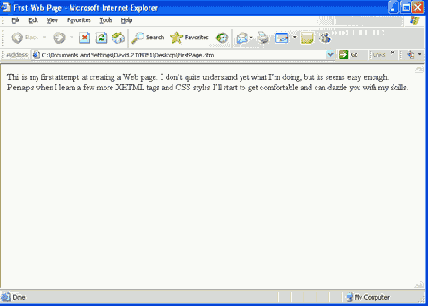
Рис. 1.21. Вывод в браузере первой страницы Web
Обратите внимание, что этот вывод браузера не является полноразмерным окном, поэтому длины строк могут выглядеть немного иначе. Это различие иллюстрирует тот факт, что браузер выводит документ в соответствии с размерами своего окна вывода. Длины строк любого текста на странице будут согласованы и перенесены по словам в соответствии с шириной окна, независимо от размера окна.
Теперь, имея общее представление о процессе кодирования и просмотра страниц Web, можно начинать изучать теги XHTML, чтобы сделать свои документы более привлекательными. В следующем разделе учебника представлены теги, которые управляют структурой страниц Web и методами вывода блоков текста.
Некоторые средства кодирования страницы Web,
Некоторые средства кодирования страницы Web, описанные в этом учебнике, основываются на более старых методах кодирования, которые все еще применяются и распознаются большинством современных браузеров. Для страниц Web, содержащих эти средства, необходимо использовать стандарт XHTML 1.0. Существуют три версии этого стандарта. Страница Web может строго соответствовать стандартам XHTML 1.0, что означает использование методов кодирования, очень близких по ограничениям стандартам XHTML 1.1. Страница может находиться в переходном соответствии, что позволяет использовать исторически распространенные методы кодирования, которые не разрешают более строгие стандарты. Страница может быть в соответствии с фреймами, что позволяет разделить окно браузера на отдельные подокна (фреймы), каждое из которых может выводить разные страницы Web.
Тремя DTD соответствия, которые необходимо указывать для этих версий XHTML 1.0, являются:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
Листинг 1.4. Стандарты соответствия XHTML 1.0 (html, txt)
В этом учебнике все страницы, за исключением указанных специально, закодированы в соответствии с XHTML 1.1, что почти совпадает со стандартами XHTML 1.0 Strict. Поэтому использовать последний нет необходимости. Для тех страниц Web, которые нарушают стандарты XHTML 1.1 (и XHTML 1.0 Strict), сделаны примечания об используемом для такой страницы DTD.
Кроме того, страница Web должна указать, с каким множеством стандартов она согласована. Страница Web обозначает свое соответствие стандарту с помощью Определения типа документа (DTD), указанного в начале страницы после объявления XML. Так как основным стандартом соответствия, которому следует учебник, является XHTML 1.1, то DTD соответствия кодируется следующим образом.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
Листинг 1.3. Определение типа документа (DFD) для соответствия XHTML 1.1 (html, txt)
Создание первой страницы Web
Пришло время создать первую страницу Web и вывести ее в браузере. Эта страница не очень интересная, но она позволит познакомиться с процессом кодирования, редактирования, сохранения и вызова страницы для вывода в браузере.
Поэтому начнем с открытия редактора Notepad и ввода текста и кода, показанного на следующем листинге.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"> <head> <title>Первая страница Web</title> </head> <body>
<!-- Здесь находится параграф для вывода в браузере -->
<p>Это первая попытка создать страницу Web. Я еще не совсем понимаю, что делаю, но это, кажется, достаточно просто. Возможно, когда я немного лучше узнаю теги XHTML и стили CSS, я буду чувствовать себя уверенно и смогу поразить всех своим мастерством.</p>
</body> </html>
Листинг 1.13. Код первой страницы Web (html, txt)
При вводе параграфа текста не обязательно вводить его строку за строкой, как в примере. Если используемый редактор выполняет автоматический перенос строк, то можно этим воспользоваться; иначе, и, возможно, предпочтительнее, использовать разрывы строк, чтобы поддерживать согласованный формат редактирования. Помните, что браузер игнорирует любые пробелы, табуляцию и пустые строки, которые вводятся в редакторе, поэтому можно вводить информацию так, чтобы ее было удобно читать.

Рис. 1.20. Кодирование страницы Web в Notepad
Создание присутствия в Web
Хотя для создания и вывода Web-страниц не требуется соединение с Интернет, но если желательно сделать эти страницы доступными другим людям - друзьям и соседям во всем мире - потребуется скопировать страницы на Web-сервер, соединенный с Интернет. Если вы пользуетесь услугами Интернет дома или на работе, то вполне возможно, что поставщик услуг Интернет (ISP) предоставляет вам домашний каталог для хранения персональных Web-страниц. Обычно соединение с этим каталогом и загрузка туда страниц выполняется очень просто. В этом случае даже те страницы, которые будут созданы с помощью этого учебника, станут доступны всему миру. Провайдер Интернет предоставит также адрес URL, необходимый для доступа к этим страницам через Интернет.
Стандарты кодирования XHTML
Этот учебник пытается выдержать баланс между строгим следованием XHTML 1.1 (текущим стандартом) и популярными оставленными свойствами HTML, включенными в XHTML 1.0. Основное содержание основывается на XHTML 1.1, однако дополнительные разделы представляют свойства XHTML 1.0, которые все еще популярны и распознаются современными браузерами.
При создании страниц Web рекомендуется включать кодирование, чтобы указать стандарт W3C, которому будет следовать кодирование. Поэтому желательно, чтобы все страницы Web включали следующую начальную строку кода для указания, что документ Web является фактически документом XML:
<?xml version="1.0" encoding="UTF-8"?>
Листинг 1.2. Объявление XML для страницы Web (html, txt)
Стандарты соответствия кодированию
В заключение еще раз подчеркнем, что любая создаваемая страница Web должна включать начальные строки кода для указания соответствия стандарту, применяемому к странице. Листинг 1.6 задает компоновку страницы Web, которая применима для большинства страниц, показанных в этом учебнике, и указывает на соответствие стандарту XHTML 1.1. В этот пример включен дополнительный код создания полной страницы Web для вывода форматированной строки текста, показанной выше на рисунке 1.10.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"> <head> <title>Страница Web, соответствующая XHTML 1.1</title> </head> <body>
<h2>Форматировать эту строку текста.</h2>
</body> </html>
Листинг 1.6. Код для указания соответствия страницы стандартам XHTML 1.1 (html, txt)
Страницы Web в этом учебнике, которые не строго соответствуют стандартам XHTML 1.1, могут использовать стандарты XHTML 1.0 Transitional. Эти страницы имеют в начале код, показанный на листинге 1.7.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"> <head> <title>Страница Web, соответствующая XHTML 1.0 Transitional</title> </head> <body>
<h2>Форматировать эту строку текста.</h2>
</body> </html>
Листинг 1.7. Код, указывающий на соответствие страницы стандартам XHTML 1.0 Transitional (html, txt)
Далее в учебнике всегда уточняется, какой из двух стандартов необходимо указывать при создании страницы Web.
Тег <body>
Основная часть кода документа XHTML находится в разделе тела документа <body>, обрамленного контейнерным тегом <body>. Только та информация, которая появляется внутри этого тега, выводится в окне браузера. В своей простейшей форме раздел тела содержит обычный текст, который выводится стилем используемого по умолчанию шрифта в окне браузера. Браузеры обычно выводят текст с помощью шрифта Times New Roman и размером примерно 12 пунктов.
Все страницы Web начинаются с этой базовой структуры документа. Затем <body> документа увеличивается в объеме за счет текста и других элементов страницы, которые должны выводиться в окне браузера. Различные комбинации этих выводимых элементов и управление их представлением выполняется с помощью дополнительных тегов XHTML.
Чтобы увидеть результат, не обязательно соединяться с Интернет или с сервером в WWW. Всю работу можно делать локально. Если провайдер Интернет, услугами которого пользуется читатель, предоставляет персональные домашние каталоги, то можно копировать документы в свой каталог для просмотра в Web. Однако для целей данного учебника можно создавать страницы Web на жестком диске персонального компьютера, на сменном флеш-драйве или дискете и просматривать страницы с помощью браузера.
Страницы Web, созданные в этом учебнике, выглядят корректно в Internet Explorer и других браузерах, которые следуют стандартам W3C.
Тег <head>
Контейнерный тег <head> обрамляет раздел заголовка документа XHTML. Раздел заголовка содержит название документа (title) вместе с другой информацией, связанной с форматированием и индексированием документа. В данный момент в разделе заголовка имеется только тег title. Другие теги, которые могут находиться в разделе заголовка, будут рассмотрены по мере необходимости.
<head> <title> здесь находится название документа </title> </head>
Листинг 1.12. Раздел заголовка <head> (html, txt)
Тег <html>
Контейнерный тег <html> (обрамляет, окаймляет, охватывает) окружает весь код XHTML в документе. Этот тег указывает, что обрамленная информация содержит код XHTML и должна интерпретироваться соответствующим образом в браузере. В соответствии со стандартами XHTML открывающий тег включает ссылку на расположение пространства имен стандартов валидации, которые будут применяться к этому документу вместе с атрибутами, определяющими используемый язык, в данном случае английский (en).
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
Листинг 1.11. Тег <html> (html, txt)
Тег <title>
Контейнерный тег <title> добавляет в документ название. Этот тег обрамляет строку текста, которая появляется в строке заголовка браузера, когда открывается страница. Тег <title> содержит идентификационную информацию о странице, полезную посетителю различных страниц Web-сайта. Отметим, что разделы <head> и <title> необходимы для соответствия стандартам XHTML 1.1.

Рис. 1.15. содержимого тега <title> в панели заголовка браузера
Теги XHTML и стили CSS
Страница Web начинается как стандартный текстовый файл, содержащий информацию, которая будет выводиться, и инструкции форматирования для ее представления на экране компьютера. Эти инструкции форматирования написаны на специальном языке разметки, называемом так, потому что он используется для "разметки" информации на странице, чтобы описать ее расположение и представление при выводе в браузере Web.
Техническая конвергенция
Интернет возник в результате сближения множества технологий, которые соединились с целью электронного обмена информацией. Сегодня Интернет является сетью взаимосвязанных сетей, которые используют общие коммуникационные протоколы, или правила обмена, для передачи информации между компьютерами. Одним из этих протоколов является Протокол передачи гипертекста - HTTP, который управляет обменом между компьютерами гипертекстовыми документами или страницами Web. Процесс обмена информацией, который применяет этот протокол, в своей совокупности называется Всемирной паутиной (WWW - World Wide Web ). Другими протоколами Интернет являются Протокол передачи файлов (FTP - File Transfer Protocol), а также Простой протокол пересылки почты (SMTP - Simple Mail Transfer Protocol), который используется для обмена сообщениями e-mail. Интернет не является единой сущностью. Он объединяет множество различных способов поддержания и обмена информацией среди множества различных компьютеров во множестве различных сетей, разбросанных по всему миру.
Всемирная паутина WWW является одним из таких методов сбора и обмена информацией. Она основывается на использовании страниц Web в качестве механизма упаковки и передачи информации между компьютерами, соединенными с Интернет. Страница Web включает в себя текстовую информацию вместе со ссылками на связанную с ней текстовую или графическую информацию (контент), находящуюся где-то в другом месте в Интернет. Эта информация форматируется для представления с помощью языка разметки гипертекста (HTML), чтобы организовать и определить стиль представленной информации и связать с другим контентом на отдаленных компьютерах. Этот язык форматирования является ключом, который открывает всемирные хранилища информации, чтобы представить ее на настольном компьютере, и это также средство для того, чтобы поделиться личной информацией с миром.
С тех начальных дней WWW выросла в основную инфраструктуру распространения информации в мире. Отдельный человек может организовать свое присутствие в Web, доступное любому другому человеку в мире, имеющему соединение с Интернет; отдельная компания может организовать сайт Web, чтобы занять свое место на глобальном рынке товаров и услуг. Хотя Web начиналась как публичная служба с ограниченной областью деятельности, сегодня она разрослась, благодаря предпринимательской деятельности отдельных индивидуумов и организаций, в то, что определяет ее название - во всемирную паутину взаимосвязанных сетей для осуществления публичных и частных мероприятий мирового сообщества.
Технологии Интернет
В недавнем прошлом соединение с Интернет было по большей части медленным. Пользователи были ограничены использованием существующих телефонных линий с ненадежными коммутируемыми соединениями. Большинство пользователей соединялись с Интернет со скоростью, ограниченной сверху 56000 бит информации в секунду. Однако последние годы отмечены значительным ростом скорости Интернет за счет применения технологии DSL и кабельных модемов со скоростями до 5000000 бит в секунду. Эти широкополосные соединения с Интернет продолжают развиваться в США и во всем мире. Как показано в таблице 1.3 к середине 2005 г. большинство домашних пользователей использовали высокоскоростной доступ к Интернет.
Таблица 1.3. Скорость соединения с Интернет
СкоростьПроцент пользователей| DSL и кабель | 58.7% |
| Модем 56К | 33.9% |
| Модем 28.8/33.6К | 5.1% |
| Модем 14.4К | 2.5% |
Источник: WebSiteOptimization.com (http://www.websiteoptimization.com/bw/0505/)
Большинство работающих в США также имеют высокоскоростные линии связи с Интернет через сетевые соединения своих компаний. В середине 2005 г. более 80% работников имели доступ к высокоскоростным соединениям.
При разработке Web-страниц важно знать целевые браузеры, которые будут использовать посетители сайта. Браузеры различаются используемыми технологиями и степенью поддержки общих стандартов. Нет никаких гарантий, что Web-страница будет выводиться одинаково или даже правильно в двух различных браузерах. Представленная в таблице 1.4 статистика по процентному распределению используемых браузеров показывает, что Microsoft Internet Explorer все еще остается наиболее широко распространенным браузером. Его популярность обусловлена в большой степени тем, что он установлен уже при продаже на большинстве ПК, покупаемых частными пользователями и организациями.
Таблица 1.4. Использование браузеров
БраузерПроцент использования| Internet Explorer | 84.0% |
| AOL, Firefox, Mozilla, Netscape | 10.0% |
| Safari | 2.0% |
| Opera | 1.0% |
| Navigator | 0.5% |
| Другие | 2.5% |
Источник: Browser News (http://www.upsdell.com/BrowserNews/index.htm)
При проектировании Web-страниц для известной аудитории с известным браузером усилия по разработке становятся относительно легкими. Страницы необходимо тестировать только в определенном браузере. Однако при проектировании для общего доступа необходимо делать предположения о наиболее вероятной аудитории.
В идеале, надо протестировать страницы во всех наиболее популярных браузерах, например, в Internet Explorer и Firefox. Как правило, при следовании стандартам W3C, представленным в этом учебнике, страницы будут иметь наилучшие шансы правильного вывода во всех браузерах, которые следуют этим стандартам.
Все современные мониторы ПК могут работать с разрешением экрана 1024 x 768 (пикселей), и многие пользователи выбирают это разрешение для вывода Web-страниц. Тем не менее, до сих пор достаточно много пользователей ограничены в выборе или выбирают разрешение дисплея 800 x 600. Очень немногие в настоящее время пользуются устаревшими дисплеями 640 x 480. Безопасный подход состоит в проектировании Web-страниц для разрешения дисплея 800 x 600, если нет полной уверенности, что предполагаемая аудитория предпочитает большие размеры страниц, возможно, с более высокими разрешениями. Так как технология развивается очень быстро, то очень скоро разрешение 1024 x 768 станет минимальным стандартом.
Необходимо отметить, что разрешение экрана не связано с размером экрана. Даже маленькие экраны (например, 15" или 17") можно настроить для вывода высокого разрешения, в зависимости от объема установленной в системе видеопамяти. Тем не менее, размер окна, в котором открывается браузер, может оказать значительное влияние на вывод страницы Web. Полноэкранный вывод страницы обычно отличается от страницы, открытой в окне меньшего размера, так как страница согласовывает свою компоновку с размером окна. Эта автоматическая настройка позволяет странице расширяться или сжиматься в соответствии с выбранной шириной окна, делая менее важным проектирование для определенного разрешения экрана или определенного размера окна.
При выводе на странице цветной графики необходимо учитывать глубину цвета (диапазон цветов) мониторов. Обычно используются режимы с трехцветным представлением. Пользователи с более старыми ПК имеют обычно 8-битные мониторы (256 цветов), число таких пользователей составляет не более 1%. Другие пользователи имеют обычно 16-битные (65,536 цветов) и 24-битные (16,777,216 цветов) мониторы, представляющие примерно 18% и 72%, соответственно. При создании собственной графики есть возможность выбора выводимой глубины цвета. При использовании готовой графики такой возможности может не быть. Помните, что изображения, сохраненные с большой глубиной цвета, могут выводиться с неправильными цветами на мониторах с небольшим объемом видеопамяти и меньшим количеством возможных цветов.
С учетом тенденций развития технологий Web разработчики Web могут рассчитывать, что современные компьютерные системы будут только совершенствоваться. Это означает, что при создании Web-страниц можно использовать самые современные технологии Web, так как количество пользователей, применяющих более старые технологии, постоянно сокращается. Оптимальным является разработка для браузера Internet Explorer, работающим с разрешением 800 x 600 пикселей и глубиной цвета 24 бита в полноэкранном окне. Можно делать настройку для других браузеров, других разрешений экрана и другой глубины цвета, если предполагается посещение страницы пользователями с другими технологиями.
Типы тегов XHTML
Коды форматирования XHTML, или теги, располагаются вокруг форматируемого материала и заключены в треугольные скобки ("<" и ">"), чтобы выделить их как инструкции разметки. На основе этих тегов разметки браузер выводит страницу с указанной компоновкой и стилем. Каждая страница Web описывается своим собственным отдельным документом XHTML, содержащим все теги, которые необходимы для структурирования и задания стиля страницы, согласно замыслам автора страницы.
Для различных задач компоновки и определения стилей используются разные типы тегов XHTML. Представленный ниже список является одним из способов классификации тегов согласно их основному применению.
Теги компоновки документа. Эти теги используются для структурирования документа XHTML. Они организуют информационное содержание (контент) страницы таким образом, что текстовые и графические элементы появляются там, где автор желает их видеть. Эти теги применяются для организации общих физических и визуальных отношений между элементами страницы.
Теги форматирования текста. Эти теги используются для задания определенного шрифта, стиля, размера и цвета текста, выводимого на странице. Они формируют и украшают текстовый контент страницы.
Теги форматирования списков. Для организации текстовой информации в списки используются специальные теги. Списковые структуры включают маркированные списки, нумерованные списки и другие.
Теги форматирования графики. Эти теги применяются для позиционирования, задания размера и стиля выводимых на странице графических изображений.
Теги ссылок. Страницы Web являются гипертекстовыми документами, что означает существование между ними связей. С помощью щелчка мыши можно немедленно перейти с одной страницы на другую или с одной страницы в определенное место на другой странице. Нет необходимости перемещаться по страницам последовательно. Поэтому используются специальные теги для задания этих связей между страницами и между различными частями одной страницы.
Теги таблиц. Страницы Web содержат информацию для посетителей; они выводят данные. Часто данные необходимо представить в табличной форме, с помощью строк и столбцов, для лучшего представления, для удобочитаемости, и облегчения понимания. Теги таблиц позволяют организовать данные в таблицы; их можно использовать также как средство структуризации для организации всего контента страниц Web.
Теги фреймов. Страницы Web можно организовать в виде фреймов или, говоря иначе, с помощью доступных одновременно отдельных окон, каждое из которых содержит отдельную страницу Web. Теги фреймов позволяют организовать такую структуру для размещения информации на странице.
Теги форм. Формы являются средствами сбора данных. Они используются для сбора информации от посетителей, чтобы получить данные для обработки или выяснить мнение пользователей о выводимом контенте сайта. Формы являются механизмом, с помощью которого посетители взаимодействуют со страницей Web. Ряд различных тегов форм предоставляют различные средства взаимодействия пользователей.
Теги мультимедиа. Современные страницы Web часто включают в себя мультимедийное содержимое, выводя аудио- и видеоинформацию и представления, кроме текста и графических изображений. Используются специальные теги для соединения и воспроизведения аудио- и видеофайлов с помощью специальных медиа-проигрывателей, которые могут быть встроены в страницу Web.
Данный учебник структурирован вокруг этих типов тегов. Вначале будут рассмотрены различные способы организации и оформления текста для представления страницы Web. Затем рассматривается вывод графических изображений и использование текста и изображений в качестве ссылок на другие страницы Web. После этого будут рассмотрены специальные средства форматирования контента с помощью таблиц, фреймов, и форм, далее следует интеграция на страницу мультимедийного контента. В конечном счете, будут рассмотрены большинство тегов XHTML, которые нужны для организации и оформления контента страницы в соответствии с самыми строгими требованиями.
URI
Хотя термин "URL" используется повсеместно, более точно называть Web-адрес URI (Uniform Resource Identifier - Единообразный идентификатор ресурса). Этот термин подчеркивает, что ресурсы Web являются чем-то большим, чем просто страницами Web; они могут быть графическими изображениями, файлами мультимедиа, загружаемыми файлами текстового процессора, электронной таблицы, и базы данных, электронными почтовыми ящиками и множеством других типов документов и служб Web.
Когда Web-документ найден, он извлекается сервером и посылается назад через Интернет запрашивающему ПК. Клиентский ПК идентифицируется в Интернет таким же образом, как и сервер. Он имеет уникальный IP-адрес, который передается на сервер вместе с URL запроса Web-страницы.
Пользователь может не знать IP-адрес своего компьютера, но он присваивается ему поставщиком услуг Интернет (ISP) при соединении с Интернет. Поэтому Web-сервер может доставить страницу сразу запрашивающему ПК.
Валидация страниц Web
Консорциум WWW обеспечивает службу валидации страниц Web для проверки страницы на соответствие стандартам. Хотя проверка страниц на соответствие не требуется для вывода страниц в браузере, но все-таки желательно выполнять валидацию страниц, чтобы убедиться, что они на самом деле соответствуют стандартам.
Служба валидации W3C доступна по адресу: http://validator.w3.org. По этому адресу находится страница, показанная на рисунке 1.12.
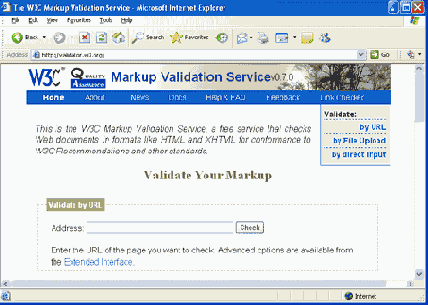
Рис. 1.12. Страница валидатора W3C
Существует три возможности для проверки страниц. Можно ввести URL страницы (убедившись, что страница доступна в Web), можно загрузить документ Web со своего локального ПК или можно скопировать свой код в текстовое поле. Последний метод показан на рисунке 1.13, где для валидации введен код страницы примера, приведенного на листинге 1.6.
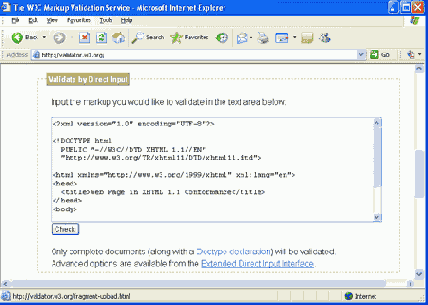
Рис. 1.13. Ввод страницы Web для валидации
Так как запись !DOCTYPE на этой странице указывает на соответствие стандартам XHTML 1.1, то страница проверяется согласно этим стандартам. После нажатия кнопки "Check" выполняется валидация и выводится страница отчета.
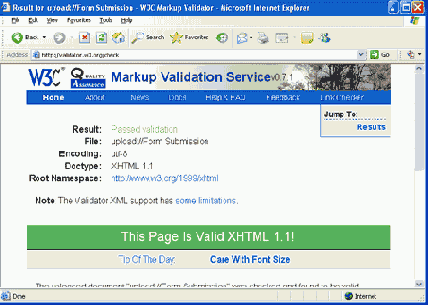
Рис. 1.14. Отчет валидатора
В данном случае код XHTML соответствует стандартам. Если документ не соответствует стандартам, выводятся сообщения об ошибках, указывающие те элементы страницы, которые являются некорректными. Помните, однако, что браузеры Web имеют склонность прощать некорректный код. Страница, скорее всего, выведется правильно, даже если она не соответствует точно стандартам.
Вывод документа XHTML
Сохраненный документ HTML с расширением .htm готов теперь для просмотра в браузере. Можно открыть документ сразу в браузере, делая двойной щелчок на его значке, или можно открыть браузер и воспользоваться меню File, чтобы найти соответствующий диск, папку и документ. Когда документ загружается в браузер, появляющийся в поле адреса браузера адрес указывает этот путь доступа к документу.
WWW - Информационная сеть
Хотя e-mail и пересылка файлов были важны для развития Интернет, они не обладали удобными методами, которые необходимы пользователям-новичкам, чтобы получить доступ к растущим хранилищам информации, разбросанным по всему миру. Все еще было слишком много технических проблем, связанных с коммуникацией через Интернет. Реализация задачи создания информационной супермагистрали требовала развития инструментов для "сокрытия" технологии Интернет за удобным для человека интерфейсом. Это привело к развитию Всемирной паутины (WWW) и программного обеспечения браузеров Интернет.

Рис. 1.4. Тед Нельсон
В середине 1960-х Тед Нельсон создал слово "гипертекст" для описания системы непоследовательных ссылок внутри текста. Идея состояла в том, чтобы перемещаться по текстовым ссылкам, не читая при этом материал в линейной последовательности. Фрагмент информации в одном месте будет вести к родственной информации в другом месте через цепочку ссылок, чтобы собрать сведения из различных источников, разбросанных по множеству документов. И только пятнадцать лет спустя Тим Бернерс-Ли, работавший консультантом в Европейском центре ядерных исследований (CERN), написал программу с названием "Enquire-Within-Upon-Everything" ("Задай любой вопрос"), которая позволяла создавать ссылки между произвольными узлами текста в документе. Каждый узел имел заглавие-идентификатор и список двунаправленных ссылок, поэтому читатели могли перемещаться из одного раздела документа в другой, активируя текстовые ссылки.

Рис. 1.5. Тим Бернерс-Ли
В 1990 Бернерс-Ли начал работу над гипертекстовым "браузером". Он придумал термин "WorldWideWeb" ("Всемирная паутина") для названия программы и "World Wide Web" - для названия проекта. Проект WWW был первоначально разработан для создания распределенной гипермедийной системы, которая была легко доступна из любого настольного компьютера, и для согласования физических исследований, разбросанных по всему миру. Web содержала стандартные форматы для текста, графики, звука и видео, которые легко индексировались и были доступны для поиска всем сетевым машинам. Были предложены стандарты для Единообразного локатора ресурса (URL - Uniform Resource Locator), который является схемой адресации Web; Протокола передачи гипертекста (HTTP - HyperText Transfer Protocol), который является множеством сетевых правил для передачи Web-страниц; и Языка разметки гипертекста (HTML - HyperText Markup Language), который является темой данного учебника.
Прототип браузера был написан для компьютера Apple Next, который был не очень широко распространен. Была создана упрощенная версия, которая подходила для любой компьютерной платформы, так называемый "Line-Mode Browser" ("Построчный браузер"), и выпущена центром CERN как свободно доступная программа (freeware). Бернерс-Ли позднее переехал на работу в MIT (Массачусетский институт технологии) и помог создать Консорциум WWW (W3С), который сегодня поддерживает стандарты технологий Web.
В январе 1993 г. Марк Андреессен, который работал в Национальном центре суперкомпьютерных приложений (NCSA) в Университите Иллинойса, выпустил версию своего нового графического браузера для Web на основе принципа "укажи и щелкни" для работы на машинах Unix. В августе Андреессен и его коллеги по NCSA выпустили бесплатные версии для Macintosh и Windows. Андреессен и Эрик Бина разработали браузер Mosaic, а позже основали корпорацию Netscape для производства его потомка браузера Navigator, одного из первых и наиболее популярных коммерческих браузеров. В августе 1994 г. NCSA передала все коммерческие права на браузер Mosaic компании Spyglass, Inc. Spyglass впоследствии лицензировала эту технологию нескольким другим компаниям, включая Microsoft, для использования в Internet Explorer.
И только в 1996 г. компания Microsoft стала основным игроком на рынке браузеров. Сегодня Internet Explorer является наиболее широко распространенным браузером, которым пользуется во всем мире около 84% пользователей Интернет.
Блочные и линейные теги
Тег <p> называется блочным (block-level) тегом. Он создает разрыв строки и начинает выводить свое содержимое в браузере с новой строки. После вывода его содержимого создается еще один разрыв строки, определяя блок текста, выделенного в браузере среди окружающего содержимого. Все объединения контента на странице Web должны появляются внутри блочных тегов.
Блочный тег отличается от линейного (in-line) тега, который не порождает разрыв строки. Включенное в него содержимое встраивается в строку в потоке элементов страницы, отделяемых обычно от окружающего содержимого одиночным пробелом. Большинство тегов XHTML являются линейными тегами.
Важно помнить об этом различии между блочными и линейными тегами. Согласно стандартам XHTML 1.1, все содержимое должно кодироваться внутри блочных тегов, чтобы идентифицировать эти отдельные блоки контента, которые составляют страницу. Точно так же все линейные теги должны располагаться внутри блочных тегов; то есть, линейное содержимое должно помещаться внутри блока текста, а не появляться независимо вне блока текста. В данном учебнике различные теги определяют как блочные и линейные, и постоянно напоминается о необходимости всегда размещать линейные элементы страницы внутри блочных элементов страницы.
Цвет ссылок
В зависимости от настроек браузера текстовые ссылки выводятся различным цветом, определяя визуально статус ссылки. До первого посещения связанной страницы текстовая ссылка на нее выводится синим цветом. После посещения страницы ссылка изменяет свой цвет на пурпурный. Можно сразу видеть, какие страницы были посещены, а какие - нет.
В дальнейшем мы узнаем, как можно изменить при кодировании ссылок эти цвета, которые используются по умолчанию.
Форматированный текст
Мы можем очень легко вернуться в редактор Notepad и вставить несколько основных тегов XHTML для организации текста для вывода в браузере. В данном случае, как показано на рисунке 2.3, теги параграфов (контейнерные теги, кодируемые как <p>) ограничивают отдельные параграфы, а тег заголовка (контейнерный тег, кодируемый как <h2>) обрамляет строку заголовка.
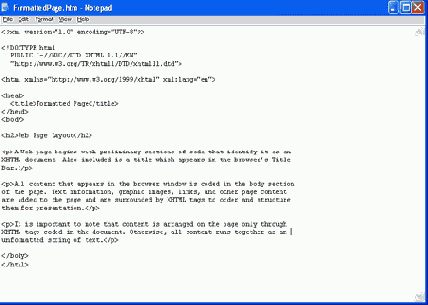
Рис. 2.3. Форматированный документ Web в редакторе Notepad
Теперь, когда страница будет открыта в браузере, эти теги приведут к тому, что блоки текста будут выводиться как отдельные параграфы, что показано на рисунке 2.4. Форматирование не слишком изысканное, но оно иллюстрирует тот факт, что компоновка элементов страницы управляется исключительно присутствующими в документе тегами XHTML.
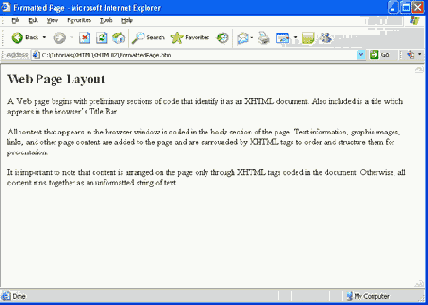
Рис. 2.4. Вывод форматированной страницы Web в браузере
Несколько следующих параграфов рассматривают основное множество тегов XHTML для организации порядка и структурного форматирования содержимого страницы. Прежде всего, представлена организация текста, затем вводятся основные теги для добавления графических изображений и ссылок. Примеры достаточно простые с точки зрения оформления. Однако в данный момент необходимо изучить структурные аспекты проектирования страниц. Средства оформления будут изучаться в дальнейшем.
Горизонтальная линейка
Основным способом выделения и идентификации разделов страницы Web является применение заголовков и подзаголовков, кодируемых с помощью тегов <hn>. Различные части страницы Web можно также визуально разделить, проводя между ними горизонтальные линейки. Это делается с помощью блочного тега <hr/> (horizontal rule) для вычерчивания через страницу линии разделения. Общий формат этого тега показан в листинге 2-13.
<hr/>
Листинг 2.13. Общая форма тега <hr/> (html, txt)
Тег <hr/> вызывает перенос строки и вывод линейки на новой отдельной строке. По умолчанию используется линейка толщиной 2 пикселя и проходящая по всей ширине окна браузера. Линейка, показанная на рисунке 2.11, порождается тегом <hr/>, записанным на отдельной строке, как показано на листинге 2-14.
<h2>Горизонтальная линейка</h2>
<p>Горизонтальная линейка используется для разделения отдельных частей содержимого страницы. Далее показана используемая по умолчанию линейка.</p>
<hr/>
<p>Линейка имеет толщину 2 пикселя и проходит по ширине через все окно браузера. Перед и после нее вставляется пустая строка.</p>
Листинг 2.14. Код для создания горизонтальной линейки между двумя параграфами (html, txt)
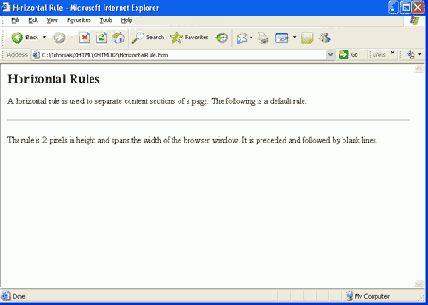
Рис. 2.11. Используемая по умолчанию горизонтальная линейка
Далее в учебнике мы узнаем, как оформить горизонтальную линейку, задавая ее толщину, ширину, цвет, выравнивание и характеристики вывода. Для текущих целей используемая по умолчанию линейка может быть визуально эффективна для разбиения слишком длинных фрагментов текста или указания логических пауз в контенте.
Графические форматы
Существует три популярных графических формата, которые применяются для изображений Web.
Формат GIF (Graphics Interchange Format) используется наиболее широко. Изображения, сохраненные в этом формате, имеют расширение .gif. Формат GIF может выводить черно-белые изображения, полутоновые или цветные. Наиболее часто он применяется для штриховых рисунков, логотипов, пиктограмм, и других изображений с ограниченным набором цветов и обычно не используется для изображений с непрерывно изменяющимися цветами, таких, как фотографии.
Формат PNG (Portable Network Graphics) был создан с целью замены формата GIF. PNG имеет по сравнению с GIF улучшенное качество изображений, предлагая в то же время лучшую степень сжатия. Однако он не поддерживает анимированные изображения. Файлы PNG используют расширение .png.
Формат JPEG (Joint Photographic Experts Group) был создан для хранения фотографических изображений. Он может представлять миллионы цветов и использует методы сжатия, позволяющие упаковать всю эту информацию о цветах в файлы небольшого размера. Изображения, сохраненные в этом формате, обычно имеют расширение файла .jpg.
На странице Web можно выводить изображения, полученные с помощью цифровой камеры или отсканированные с фотографии, или можно скопировать изображения из публичных коллекций репродукций в Web. Если у вас есть программа какого-либо из популярных редакторов графических изображений, то обычно достаточно просто можно отредактировать, изменить размер и преобразовать цифровые фотографии или отсканированные изображения в форматы Web. Для вывода на своих страницах Web сохраните просто эти изображения в формате GIF, PNG, или JPEG. Другие форматы также могут правильно выводиться в браузере, однако большие размеры их файлов могут быть неудобны для посетителей, которые должны будут их загружать при доступе к Web.
Исключенное выравнивание изображений
Горизонтальное положение изображения можно контролировать, размещая тег <img/> внутри тега <p>, который выравнивает изображение влево, вправо или центрирует на линии. Выравнивание параграфа может использовать исключенный атрибут align="left|center|right" тега <p>. Изображение ниже, например, будет центрировано на отдельной линии и будет окружено пустыми строками с помощью ограничивающего тега <p>.
<p align="center"><img src="Stonehenge.jpg" alt="Изображение Стоунхенджа"/></p>

Позже мы подробнее познакомимся с размещением и выравниванием изображений на странице. В данное время считайте использование атрибута параграфа align только временным способом выравнивания изображений.
Исключенные атрибуты type и start
Атрибут type может использоваться внутри открывающего тега <ol>, чтобы определить один из пяти различных символов нумерации. Значением атрибута может быть type="1" для десятичных чисел (по умолчанию), type="A" для букв верхнего регистра, type="a" для букв нижнего регистра, type="I" для римских цифр верхнего регистра и type="i" для римских цифр нижнего регистра. Например, тег ol type="A" порождает следующий список упорядоченных по алфавиту элементов.
A. Элемент списка 1 B. Элемент списка 2 C. Элемент списка 3
Можно определить значение, начинающее последовательность упорядоченного списка, задавая необязательный атрибут start="n" для тега <ol>. Начальное значение последовательности требуется, например, когда упорядоченный список прерывается на странице другими элементами.
Как показано ниже, два последовательно упорядоченных списка разделены параграфом. Первый список начинается с "A" и продолжается до "E", так как в списке имеется пять элементов. Второй список необходимо начать с шестой буквы "F". Если начальное значение не определено, то упорядочивание снова начнется с "A".
Это начало списка:
A. Элемент списка A B. Элемент списка B C. Элемент списка C D. Элемент списка D E. Элемент списка E
Это продолжение списка:
F. Элемент списка F G. Элемент списка G H. Элемент списка H I. Элемент списка I J. Элемент списка J
Код этого списка показан ниже. Первый упорядоченный список использует буквы верхнего регистра (type="A"), начиная с "A" и заканчивая "Е". Второй список переопределяет эту последовательность по умолчанию, определяя start="6" в открывающем теге <ol>. Таким образом, второй список последовательно упорядочивается от "F" до "J".
<p>Это начало списка:</p>
<ol type="A"> <li>Элемент списка A</li> <li>Элемент списка B</li> <li>Элемент списка C</li> <li>Элемент списка D</li> <li>Элемент списка E</li> </ol>
<p>Это продолжение списка:</p>
<ol type="A" start="6"> <li>Элемент списка F</li> <li>Элемент списка G</li> <li>Элемент списка H</li> <li>Элемент списка I</li> <li>Элемент списка J</li> </ol>
Исключенные атрибуты width и height
Загруженное изображение может иметь размер, не соответствующий тому, который требуется на странице. Лучшим решением будет использование графического редактора для изменения размера или обрезки изображения по требуемым размерам до размещения его на странице. Альтернативное решение состоит в динамическом изменении размеров изображения во время вывода браузера, с применением исключенных атрибутов width и height тега <img/>.
width="n" height="n"
Размер n задается в пикселях. Необходимо задать только одну из размерностей, но не обе, чтобы сохранить пропорции изображения. Браузер автоматически настроит другой размер, чтобы сохранить правильную пропорцию изображения.
Исходный размер загруженного изображения, показанного ниже, равен 480 пикселей (ширина) на 641 пиксель (высота). Его размер изменяется во время вывода браузера с помощью следующего тега:
<img src="Flower.jpg" alt="Изображение цветка" width="200"/>
При изменении только ширины изображения браузер настроит высоту таким образом, чтобы обеспечить сохранение правильной пропорции. Даже когда браузер изменяет размер изображения, размер файла исходного изображения не изменяется. Для больших изображений это может означать избыточное время вывода, так как необходимо передавать весь файл на компьютер посетителя, прежде чем его размер будет изменен во время вывода на экран.
Дополнительная информация о размещении изображений на страницах Web представлена в дальнейшем. Пока достаточно иметь возможность скромно украсить страницу собственными изображениями или скопированными из коллекции репродукций.
Исключенные тег <hr> и его атрибуты
Тег <hr> (без закрывающей косой черты) пока еще распознается браузерами и создает такую же линейку, как и тег <hr/>. Он не действителен согласно стандартам XHTML 1.1. Тег может включать также следующие атрибуты для оформления линейки, эти атрибуты распознаются также в теге <hr/>, но являются исключенными.
align="left|center|right" size="n" width="n|n%" color="цвет"
Атрибут align смещает линейку в строке влево (по умолчанию), по центру или вправо. Атрибут size задает толщину горизонтальной линейки в пикселях. Атрибут width задает ширину линейки в пикселях или как процент от ширины окна. Линейка может выводиться как сплошная полоса при задании (без значения) и с цветом, определяемым атрибутов color. Значение цвета задается как название цвета или как шестнадцатеричное значение, определение которого будет рассмотрено в дальнейшем. Следующий код задает нестандартную линейку:
<hr align="center" size="5" width="50%" color="gray">

Так как тег <hr> исключен в текущих стандартах, то он не должен использоваться. Аналогично атрибуты выравнивания и оформления могут присваиваться новому тегу <hr/>, хотя желательно их избегать в пользу новых методов оформления, рассматриваемых в дальнейшем.
Исключенные теги и атрибуты
XHTML является заменой более старого языка HTML. Однако он сохраняет многие средства кодирования HTML, чтобы облегчить переход между двумя языками. Среди оставленных имеется несколько тегов и атрибутов тегов, которые могут кодироваться внутри тегов для изменения их характеристик вывода по умолчанию. Например, тег <p> включает атрибут align для управления выравниванием текста. При задании этого атрибута, например, <p align="center">, текст каждой строки параграфа будет выровнен по центру, а не по левому краю.
В XHTML большинство атрибутов тегов были постепенно сокращены или исключены. Они все еще распознаются браузерами ради совместимости с HTML, но настоятельно рекомендуется прекратить их использование. Вместо этого для той же цели должны использоваться более новые объявления таблиц стилей. Однако исключенные атрибуты описаны в данном учебнике, так как они могут встретиться на существующих страницах Web, хотя большинство атрибутов недействительны в стандартах XHTML 1.1.
Некоторые теги HTML также исключены в XHTML. Исключенные теги также будут представлены, так как они, скорее всего, еще встречаются на существующих страницах. Эти теги могут правильно выводиться в современных браузерах, но вместо них необходимо использовать более современные средства.
Исключенный атрибут align
По умолчанию текст параграфа выводится в браузере с переносом слов и выровненным по левому краю страницы. Однако можно выровнять текст по правому краю, центрировать его или выровнять все строки по обоим краям. Эти варианты выравнивания определяются атрибутом align внутри тега уровня блока. Общая форма кодирования этого атрибута вместе с его возможными значениями показана ниже:
align="left|center|right|justify"
Ключевому слову align присваивается одно из значений выравнивания в скобках. Например, следующий код центрирует заголовок предыдущего примера страницы и выравнивает все строки параграфа по обоим краям. Вывод в браузере показан на рисунке 2.5.
<h2 align="center">Компоновка страницы Web</h2>
<p align="justify">Страница Web начинается с предварительных разделов кода, которые определяют документ XHTML. Также включается заголовок, который появляется в панели заголовка браузера.</p>
<p align="justify"> Все содержимое, которое появляется в окне браузера, кодируется в разделе тела страницы. Текстовая информация, графические изображения, ссылки и другое содержимое страницы добавляются на страницу и ограничиваются тегами XHTML, чтобы упорядочить и структурировать их представления. </p>
<p align="justify">Важно отметить, что содержимое организовано на странице только с помощью тегов XHTML, закодированных в документе. Иначе все содержимое выводится как одна неформатированная строка текста. </p>
Листинг 2.4. Страница Web, форматированная с помощью тегов параграфа с атрибутом align (html, txt)
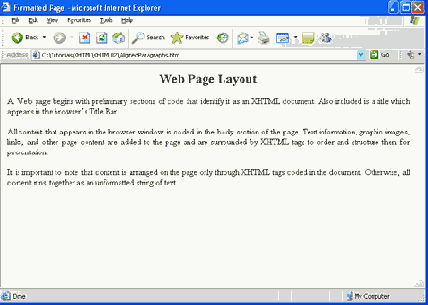
Рис. 2.5. Страница Web, форматированная с помощью выравнивания параграфов
Помните только, что атрибут align является исключенным в некоторых стандартах XHTML. Он представлен здесь как быстрый и простой способ выравнивания параграфов и будет служить удобным, но временным методом оформления, пока мы не научимся кодировать и использовать таблицы стилей на страницах Web.
Заголовки можно выравнивать слева (по умолчанию) или справа, или они могут выравниваться по центру строки с помощью атрибута
align="left|center|right"
тега <hn>. Следующий код, например, центрирует заголовок в горизонтальном направлении между краями страницы.
<h1 align="center">Центрированный заголовок</h1>
Так как align является исключенным атрибутом в стандартах XHTML, он должен использоваться для выравнивания заголовков только в качестве временного метода. В дальнейшем в учебнике рассмотрены стандарты таблиц стилей для горизонтального выравнивания текста на странице.
Исключенный атрибут target
По умолчанию страницы по ссылкам открываются в том же окне браузера, что и страница со ссылками, заменяя ее. При соединении с удаленной страницей существует риск, что посетители сайта будут переходить на удаленный сайт и в результате терять контакт с исходным сайтом. Они могут последовательно нажимать кнопку браузера Back (Назад), чтобы вернуться на сайт, но если они посетят слишком много страниц на удаленном сайте, то возврат на исходный сайт может быть практически нецелесообразен. В конце концов, ваши посетители будут потеряны на удаленном сайте.
Одним из способов решения этой проблемы является соединение с удаленными сайтами всегда в отдельном окне браузера. Достаточно просто открыть страницу в другом окне; добавьте просто атрибут target="_blank" к тегу <a>, как показано ниже для уже приведенной здесь ссылки на сайт Google.
<a href="http://www.google.com" target="_blank">Перейти на Google</a>
В этом случае посетители могут сколько угодно перемещаться по удаленному сайту во втором окне браузера и после закрытия этого окна сразу вернуться на страницу с исходной ссылкой в начальном окне.
Необходимо отметить, что атрибут target не соответствует стандартам XHTML 1.1. Его использование должно рассматриваться как временный способ открытия страниц Web в новом окне браузера. В дальнейшем будет изложен альтернативный способ, который не нарушает стандарты XHTML.
Создание текстовых ссылок, как описано здесь, представляет только пару способов, которыми гиперссылки могут связывать несколько страниц Web. В дальнейшем будут рассмотрены другие варианты ссылок и методов соединения.
Исключенный атрибут type
Атрибут type="disc|circle|square" можно задействовать внутри открывающего тега <ul>, чтобы определить стиль применяемого символа маркера, если он отличается от используемого по умолчанию диска. Текущие стандарты XHTML не рекомендуют пользоваться атрибутом type и предоставляют показанные далее другие средства для определения символов маркеров.
Исключенный тег <br>
Все браузеры все еще поддерживают тег <br>, который кодируется без закрывающей косой черты, требуемой для пустого тега XHTML. Будущие версии XHTML не будут поддерживать такой тег, поэтому лучше его не использовать.
Использование графических изображений в качестве ссылок
Графические изображения можно использовать в качестве ссылок таким же образом, как и текстовые строки. В этом случае тег <img/> помещается внутри тега <a>, чтобы сделать изображение реагирующим на щелчок мыши и соединить со страницей или сайтом, указанными в атрибуте href.
Следующее изображение скопировано с Web-сайта www.google.com и сохранено в локальном каталоге Web. Оно размещено на странице и сделано реагирующим на щелчок мыши ссылкой на сайт, открывающийся в отдельном окне браузера.
<a href="http://www.google.com"><img src="Google.gif" alt="Ссылка на Google"/></a>

Рис. 2.16. Код и вывод в браузере изображения, используемого как ссылка
Отметим, что приведенное выше изображение может быть окружено рамкой. Таким же образом, как подчеркиваются текстовые строки, используемые как ссылки, графические изображение, используемые как ссылки, выводятся с рамкой. Рамка служит графическим индикатором того, что изображение является ссылкой. Можно удалить рамку с помощью исключенного атрибута border="0" тега <img/>. В дальнейшем будут описаны более современные методы работы с рамками.
Использование изображений
Кто-то может обладать талантом создавать свои собственные графические изображения, но большинству, вероятно, это не дано. Поэтому может понадобиться поискать существующие иллюстрации, которые будут дополнять текстовое содержимое на страницах. Web является богатым источником графики, и в сети существует множество изображений, которые можно использовать. Можно воспользоваться поисковой машиной, чтобы найти сайты репродукций, где можно выбирать из миллионов изображений. Иллюстрация на рисунке 2.13 показывает результаты поиска Google, содержащего более 32 миллионов источников репродукций.
Рис. 2.13. Результаты поиска сайтов репродукций
После того как необходимое изображение найдено, его можно легко загрузить для использования. Как показано на рисунке 2.14, сделайте щелчок правой кнопкой мыши на изображении и выберите из контекстного меню позицию Save Picture As (Сохранить изображение как...). В диалоговом окне Save (Сохранить) выберите место на своем ПК для загрузки изображения. Этим местом может быть каталог страницы Web, на которой будет выводиться изображение, или можно создать отдельный подкаталог для хранения таких файлов. Можно также при желании переименовать изображение во время сохранения. Помните об авторских правах. Для использования защищенных авторским правом изображений необходимо получить соответствующее разрешение.
Рис. 2.14. Загрузка изображения из Web
Локальные ссылки
При создании сайта Web большинство создаваемых ссылок будет между страницами этого сайта. Простейшим способом хранения этих страниц для соединения является хранение их в одном месте, то есть в одном каталоге на диске или на одной дискете или устройстве хранения. В этом случае указываемый в теге <a> адрес URL является просто именем страницы.
В примере на рисунке 2.12 показаны три страницы Web с именами Home.htm, Organize.htm, и Supplement.htm. Страница Home.htm содержит текстовые ссылки на две другие страницы и имеет следующий код:
<h2>Соединение со страницами Web</h2>
<p>Перемещение между страницами сайта Web становится возможным с помощью гипертекстовых ссылок. Одно или несколько слов на странице "соединения" сделаны чувствительными к щелчкам мыши, что позволяет читателю переходить на различные "присоединенные" страницы. Существует две основные причины для разбиения темы на различные присоединенные страницы Web:</p>
<p> <a href="Organize.htm">Тематическая организация</a><br/> <a href="Supplement.htm">Дополнительная информация</a><br/> </p>
<p>При создании ссылок между страницами Web важно предоставить ссылки возврата на страницы соединения. Автор страницы не должен оставлять читателей зависшими в конце ряда ссылок, не имеющим простого способа вернуться на домашнюю страницу. </p>
Листинг 2.31. Код для соединения страниц (html, txt)
Обратите внимание на строку, содержащую код
<a href="Organize.htm">Тематическая организация</a>
Тег <a> охватывает строку текста "Тематическая организация", чтобы преобразовать ее в гиперссылку для открытия страницы Organize.htm в окне браузера. Требуется только имя этой страницы в качестве адреса URL в href, так как присоединенная страница находится в том же каталоге, что и страница Home.htm, на которой создается ссылка. Аналогично кодируется ссылка на страницу Supplement.htm. Когда происходит щелчок на любой из этих ссылок, связанная страница вызывается и загружается в браузер, заменяя страницу Home.htm.
Когда одна из страниц, Organize.htm или Supplement.htm, выводится в окне браузера, можно легко вернуться на страницу Home.htm, щелкнув на кнопке Back в панели инструментов браузера. Однако лучше закодировать свои собственные внутренние ссылки между страницами. То есть, обе страницы, Organize.htm и Supplement.htm, должны включать, как показано здесь, свои собственные ссылки возврата на страницу Home.htm.
Код страницы Organize.htm показан ниже. Здесь строка текста "Вернуться на Home" превращена в ссылку с помощью тега анкера <a>. Щелчок на этой ссылке снова открывает страницу Home.htm в окне браузера. Аналогичный код возврата на домашнюю страницу имеется на странице Supplement.htm.
<h2>Тематическая организация</h2>
<p> Одной из причин разбиения рассматриваемого вопроса в Web на отдельные страницы является слишком большой объем информации для размещения на одной странице Web. По той же причине, почему книги делятся на главы, а главы делятся на разделы, а разделы на параграфы, рассматриваемый вопрос в Web может понадобиться разделить на логические единицы, которые представлены отдельно друг от друга. Вместо представления в виде одного непрерывного потока текста рассматриваемый вопрос организуется в связанные фрагменты информации, которые напоминают о своей общей структуре и предоставляют независимое чтение отдельного частичного вопроса.</p>
<p><a href="Home.htm">Вернуться на Home</a></p>
Листинг 2.32. Код для возврата на исходную страницу (html, txt)
Способ организации ссылок между страницами полностью в распоряжении разработчика. Это зависит в большой степени от того, как сайт разделен на отдельные страницы, и того, как отдельные темы связаны друг с другом. Проверьте, что нет тупиковых страниц, где посетители не имеют возможности вернуться туда, откуда они пришли.
Несколько переносов строк
При использовании тегов <p> и <blockquote> одна пустая строка появляется перед и после вложенного текстового блока с отступами. Когда вставляют теги <br/>, чтобы закончить строки текста, никакие интервалы между строками не появляются. Однако могут быть ситуации, когда желательно вставить дополнительные пустые строки, чтобы увеличить вертикальный интервал между строками текста или между другим содержимым, присутствующим на странице. Для этой цели можно использовать тег <br/>.
Ниже представлена запись предыдущей страницы с дополнительными пустыми строками перед и после цитированного стихотворения. Эти пустые строки создаются добавлением тегов <br/>, чтобы выполнить дополнительные переносы строк. Вывод браузера показан на рисунке 2.9.
<p>Вот история о Мери и надоедливой маленькой овечке, которая повсюду ее преследовала.<br/><br/><br/></p>
<blockquote> <p>Была у Мери овечка,<br/> Была ее шерсть снежно-белой;<br/> И куда бы ни шла Мери,<br/> Овечка бежала за нею.</p> </blockquote>
<p><br/>У Мери была ужасная жизнь. Ужасно трудно сходить на свидание, когда вокруг тебя все время скачет овечка.</p>
Листинг 2.10. Страница, форматированная с помощью нескольких переносов строк (html, txt)
Рис. 2.9. Использование переноса строк для увеличения вертикального интервала на странице
Каждый тег <br/> вставляет на странице дополнительный перенос строки. Поэтому можно писать несколько тегов <br/> подряд, чтобы получить несколько пустых строк на странице.
Отметим в предыдущем примере, что теги <br/> кодируются внутри первого и последнего параграфов - внутри тегов блочного уровня <p> для совместимости со стандартами XHTML 1.1. Их можно было бы поместить также в начале и конце параграфа стихотворения внутри тега <blockquote>. Обратите внимание, что требуется три тега <br/> в конце первого параграфа, чтобы соответствовать числу пустых строк, заданных одним тегом <br/> в начале последнего параграфа. Это является особенностью способа, которым браузер обрабатывает тег в начале и конце параграфов. Может понадобиться эксперимент, чтобы определить число тегов, нужное для создания требуемого числа пустых строк.
Неупорядоченные списки
Неупорядоченный список является последовательностью элементов, перед которыми стоит символ маркера, отделяемой от окружающего текста пустыми строками. Список выводится через один интервал и с отступом от левого края. Пример вывода неупорядоченного списка в браузере показан в листинге 2.15.
Элемент списка 1 · Элемент списка 2 · Элемент списка 3
Листинг 2.15. Вывод в браузере неупорядоченного списка (html, txt)
Неупорядоченный список создается с помощью блочного контейнерного тега <ul>, который ограничивает элементы списка, определяемые блочными контейнерными тегами <li> (list item). Общая форма неупорядоченного списка показана в листинге 2.16.
<ul> <li>элемент списка</li> <li>элемент списка</li> ... </ul>
Листинг 2.16. Общая форма неупорядоченного списка (html, txt)
Например, маркированный список, показанный выше в листинге 2.15, задается следующим кодом.
<ul> <li> Элемент списка 1</li> <li> Элемент списка 2</li> <li> Элемент списка 3</li> </ul>
Листинг 2.17. Код неупорядоченного списка (html, txt)
Элементы списка выводятся через один интервал и содержат в начале символ маркера. Если текст элемента списка не умещается по ширине страницы, то он переносится по словам и делается отступ за символ маркера. Элементы могут заключаться в теги <p> (или между элементами могут вставляться теги <br/>), чтобы увеличить строчный интервал между элементами. Следующий список, например, обрамляет элементы списка тегами <p>, чтобы создать дополнительные пустые строки между записями. Вывод браузера показан в листинге 2.19.
<ul> <li><p>Это первый элемент списка. Текст, идущий после символа маркера, переносится по словам внутри маркера. Теги параграфа используются для вставки пустых строк между элементами списка.</p></li>
<li><p>Это второй элемент списка. Текст, идущий после символа маркера, переносится по словам внутри маркера. Теги параграфа используются для вставки пустых строк между элементами списка.</p></li> </ul>
Листинг 2.18. Код неупорядоченного списка параграфов текста (html, txt) Это первый элемент списка. Текст, идущий после символа маркера, переносится по словам внутри маркера. Теги параграфа используются для вставки пустых строк между элементами списка.
· Это второй элемент списка. Текст, идущий после символа маркера, переносится по словам внутри маркера. Теги параграфа используются для вставки пустых строк между элементами списка.
Листинг 2.19. Вывод в браузере неупорядоченного списка параграфов текста (html, txt)
Параграфы
Большинство страниц Web являются текстовыми документами, а самым распространенным способом организации текста на странице Web является использование параграфов. С позиции страницы Web параграф - это блок текста, перед и после которого следует пустая строка. Параграф выравнивается по левому краю страницы, и в пределах окна браузера осуществляется перенос по словам.
Перенос строки
Кодирование параграфов с помощью тегов <p> является наиболее распространенным методом структурирования текста на странице Web. Большинство страниц Web - это текстовые страницы, и параграфы являются удобными и легко читаемыми методами представления текста. Однако существуют и другие средства структуризации текста.
Соединение страниц
Первоначальной задачей Всемирной паутины (WWW) было создание механизма нелинейного доступа к информации. Чтобы обеспечить такой тип доступа, информация представляется в виде множества страниц Web, затем создаются гипертекстовые ссылки (или гиперссылки) для перемещения с одной страницы на другую в той последовательности, которую предпочитает читатель. В дальнейшем разновидности страничных ссылок будут рассмотрены более полно. Здесь мы познакомимся с основной концепцией соединения и заданием текстовых ссылок для перемещения между страницами.
Чаще всего ссылку с одной страницы на другую создают с помощью текстовой "точки доступа" на одной странице, щелчок мышью на которой открывает вторую страницу - она заменяет первую страницу в окне браузера. Строка текста, которая делается чувствительной к щелчку мыши, может быть представлена одним словом или несколькими словами, обычно намекающими на содержимое указываемой страницы. Как правило, на связанной странице присутствует вторая ссылка для возврата на исходную страницу. Считается неприличным оставить посетителей в конце последовательности ссылок без возможности вернуться на начальную страницу.
Как иллюстрирует рисунок 2.12 две текстовые ссылки вызывают переход на различные страницы. На связанных страницах имеются текстовые ссылки для возврата на исходную страницу.
Рис. 2.12. Текстовые ссылки между страницами
Создание подкаталога Media
При создании все большего количества страниц Web наступает момент, когда каталог Web начнет становиться перегруженным и дезорганизованным. Желательно, чтобы файлы документов и изображений, которые относятся к различным Web-сайтам или приложениям, хранились совместно в своих собственных отдельных подкаталогах. Такая организация облегчает поиск и работу со взаимосвязанными файлами.
Одним из распространенных способов такой организации является создание отдельного подкаталога в основном каталоге Web только для графических файлов. В этом случае все страницы Web остаются в основном каталоге Web, а все дополнительные файлы располагаются в подкаталоге. Рисунок 2.17 показывает типичную организацию каталогов Web, с вложенной папкой Media внутри основной папки Web.
Рис. 2.17. Структура каталога Web
Если будет создана эта папка Media, то относительный URL атрибута src тегов <img/> должен отражать эту структуру каталогов. Например, если Page1.htm выводит изображение Pic1.gif, файл которого расположен в папке Media, то его тег <img/> необходимо записать следующим образом:
<img src="Media/Pic1.gif" alt="Изображение Pic1"/>
Листинг 2.36. Код для доступа к изображению, расположенному в подкаталоге Media (html, txt)
Такой код указывает, что относительно каталога, где расположена страница Page1.htm, изображение Pic1.gif расположено на один уровень ниже в иерархи каталогов, внутри подкаталога Media. В дальнейшем организация страниц Web и поддерживающих файлов рассматривается подробнее. В данный момент можно начать создавать порядок в своих файлах для Web, помещая изображения в отдельный подкаталог.
Списки
XHTML позволяет структурировать текст в форме списков. Можно создавать списки маркированных элементов, списки нумерованных элементов и списки терминов и определений. Два первых типа списков похожи на строки текста через один интервал с добавлением в начале строки маркеров или чисел. Последний тип списка похож при выводе на последовательность параграфов цитирования.
Списки определений
Список определений является последовательностью терминов и определений, отделенных от окружающего текста пустыми строками. Термины в списке прижаты к левому краю; определения на следующих строках смещены от края и используют перенос слов. Пример списка определений показан в листинге 2.27.
Термин 1 Это определение Термина 1. Определяемый термин располагается на отдельной строке и за ним следует блок текста определения. Определение использует перенос слов и смещено от края. Термин 2 Это определение Термина 2. Определяемый термин располагается на отдельной строке и за ним следует блок текста определения. Определение использует перенос слов и смещено от края.
Листинг 2.27. Вывод в браузере списка определений (html, txt)
Общая форма тегов, используемых для создания списка определений, представлена в листинге 2.28.
<dl> <dt>Термин 1</dt> <dd>Текст определения Термина 1</dd> <dt>Термин 2</dt> <dd>Текст определения Термина 2</dd> ... </dl>
Листинг 2.28. Общая форма тегов списка определений (html, txt)
Список определений помещается внутри тегов <dl> и содержит один или несколько тегов <dt> (definition term), перечисляющих определяемые элементы. С каждым определяемым термином связан тег <dd> (definition description), содержащий определение термина.
Список определений, показанный выше в листинге 2.27, порождается следующим кодом.
<dl> <dt>Термин 1</dt> <dd>Это определение Термина 1. Определяемый термин располагается на отдельной строке и за ним следует блок текста определения. Определение использует перенос слов и смещено от края.</dd> <dt>Термин 2</dt> <dd>Это определение Термина 2. Определяемый термин располагается на отдельной строке и за ним следует блок текста определения. Определение использует перенос слов и смещено от края.</dd> </dl>
Листинг 2.29. Код списка определений (html, txt)
При выводе в браузере элементы списка выводятся через один интервал без пустых строк между терминами. Если необходимо увеличить межстрочный интервал, можно использовать обрамляющие определение теги <p> или теги <br/> между ними.
Список определений, конечно, можно применять и для целей, отличных от определения терминов. Если потребуется список элементов (терминов), за каждым из которых следует смещенный параграф (определение), то можно будет воспользоваться списком определений.
Структурирование содержимого страницы
Основное назначение тегов XHTML состоит в структурировании и организации текстового и графического содержимого (контента) на странице Web. Они не предназначены для оформления или украшения контента, а только для его организации, чтобы эта информация была представлена в некотором визуальном порядке для облегчения чтения и в логическом порядке для улучшения понимания.
Страница, кроме организации контента, может иметь визуальное оформление. Для текста можно использовать шрифты различного размера, цвета и типа, а для графических изображений можно изменять размер и стиль. В этом учебнике будут рассмотрены различные методы оформления, которые позволяют улучшить визуальную привлекательность текста и графических элементов. Прежде всего, однако, необходимо познакомиться с основными тегами, которые вносят порядок компоновки в содержимое страницы.
Тег <a>
Наиболее распространенным типом ссылки являются реагирующие на щелчок мыши слово или фраза, которые переносят прямо на указываемую страницу. Текстовая ссылка такого типа создается с помощью обрамляющего строку тега <a>, называемого также тегом анкера, - он определяет расположение страницы, с которой происходит соединение. Базовый формат этого тега показан в листинге 2.30.
<a href="url">текст ссылки</a>
Листинг 2.30. Общая форма тега <a> (html, txt)
Атрибут href (hypertext reference) определяет адрес URL связанной страницы. Ссылки можно делать с другими страницами на локальном сайте Web или со страницами на удаленных сайтах в любом месте WWW.
Если страница, на которую указывает ссылка, находится в том же месте (в том же каталоге), что и страница, содержащая ссылку, то URL является просто именем страницы. Такая локальная ссылка называется относительной ссылкой, так как путь доступа к указанной странице задается относительно расположения указывающей страницы.
При указании удаленного сайта адрес URL должен быть полной ссылкой Web, включающей протокол "http://", за которым следует имя домена сайта. Такая внешняя ссылка называется абсолютной ссылкой, так как путь доступа к указанной странице является полным адресом Web.
Тег <a> обрамляет строку текста, которая должна быть сделана чувствительной к щелчку мыши и которая активирует ссылку. Обычно текст описывает соединяемое место назначения. В качестве ссылки можно использовать одну букву, слово, фразу, или текст любого разумного объема. Когда происходит щелчок на этом тексте, то страница ссылки немедленно заменяется в окне браузера страницей, на которую указывает ссылка.
Тег <a> является линейным тегом - это означает, что он должен появляться внутри тега <p> или другого блочного тега, чтобы соответствовать стандартам XHTML 1.1.
Тег <blockquote>
Тег <blockquote> предлагает способ создания отступа для блока текста, чтобы сместить его относительно окружающего содержимого с целью выделения, как делается при использовании цитат в кавычках, откуда тег и получил свое имя. Этот контейнерный тег смещает вложенный текст на фиксированное число пикселей (примерно на 40) от левого и правого края. Вложенный текст переносится по словам и выделяется пустыми строками перед и после текста. Общая форма тега <blockquote> показана в листинге 2.5.
<blockquote> <p>текст</p> </blockquote>
Листинг 2.5. Общая форма тега <blockquote> (html, txt)
Отметим, что тег <blockquote> не считается тегом блочного уровня в стандартах XHTML 1.1, хотя и создает разрывы строк и пустые строки перед и после вложенного текста. Он не заменяет тег блочного уровня <p>, который требуется для вложения блока текста и смещения его относительно окружающего содержимого. Тег <blockquote> просто окружает блок параграфа, включая его обрамляющий тег <p>.
В следующем примере тег <blockquote> смещает средний параграф относительно окружающего текста. Вывод браузера показан на рисунке 2.6.
<p>Здесь три параграфа. Первый параграф форматирован с помощью стандартного тега параграфа и выровнен относительно левого края страницы.</p>
<blockquote> <p>Второй параграф форматирован с помощью тега <blockquote>, чтобы сместить его левую и правую стороны примерно на 40 пикселей от краев страницы.</p> </blockquote>
<p>Последний параграф форматирован как первый. Он помещен в стандартный тег параграфа и прижат к левому краю страницы.</p>
Листинг 2.6. текста, форматированный с помощью тега <blockquote> (html, txt)
Рис. 2.6. Применение для параграфа тега <blockquote>
Приведенная выше запись кода в редакторе показывает параграф цитирования смещенным и с пустыми строками, аналогично тому, как он выводится в браузере. Как мы знаем, форматирование редактора не требуется и не оказывает влияния на вывод браузера, который управляется только тегами XHTML. Однако лучше сделать запись в редакторе похожей на вывод браузера, чтобы можно было визуально оценить соотношения между выводимыми частями содержимого страницы. Значительно легче находить пропущенные или неправильные теги, когда запись страницы в редакторе хорошо организована.
Тег <br/>
Тег <br/> (перенос строки) заставляет браузер закончить строку текста и продолжить вывод на следующей строке в окне браузера. Он не создает, как в случае параграфов, пустые строки перед и после законченной строки текста. Общая форма для тега переноса строки показана в листинге 2.8.
<br/>
Листинг 2.8. Общая форма тега <br/> (html, txt)
Тег <br/> не является контейнерным тегом; он не охватывает текст и не имеет дополнительного закрывающего тега. Этот пустой тег просто помещают внутри текста в том месте, где должен произойти разрыв строки. Этот тег удобно применять для вывода списков объектов, стихов или других объединений отдельных текстовых строк через один интервал. Следующий код использует перенос строк, например, для завершения отдельных строк стихотворения, помещенного в тег <blockquote>.
<p>Вот история о Мери и надоедливой маленькой овечке, которая повсюду ее преследовала.</p>
<blockquote> <p>Была у Мери овечка,<br/> Была ее шерсть снежно-белой;<br/> И куда бы ни шла Мери,<br/> Овечка бежала за ней.</p> </blockquote>
<p>У Мери была ужасная жизнь. Ужасно трудно сходить на свидание, когда вокруг тебя все время скачет овечка.</p>
Листинг 2.9. Блок текста, форматированный с помощью переноса строк (html, txt)
Рис. 2.8. Использование переноса строк для вывода текста через один интервал
Четыре строки стихотворения помещены внутрь параграфа blockquoted, чтобы сместить их и отделить от окружающих параграфов. Каждая строчка стихотворения появляется на отдельной строке текста через один интервал от предыдущей строки. Важно помнить, что тег <br/> является линейным тегом, а не блочным; поэтому согласно стандартам XHTML 1.1 он не может появиться в строке сам по себе или как автономный тег. Он должен помещаться внутрь тега <p> или другого блочного тега, как это сделано в предыдущем примере.
Тег <img/>
Изображения GIF и JPEG размещают на странице Web с помощью линейного тега <img/>. Общий формат этого тега показан ниже.
<img src="url" alt="text"/>
Листинг 2.35. Общая форма тега <img> (html, txt)
Тег <img/> кодируется на странице Web в том месте, в котором должно выводиться изображение. Атрибут src задает источник или расположение файла изображения. Если файл изображения находится в том же каталоге, что и страница Web, на которой оно выводится, то в качестве URL в src достаточно указать только имя файла.
Атрибут alt является обязательным в XHTML 1.1. Его значение "text" задает краткое всплывающее описание изображения, когда указатель мыши перемещается поверх изображения. Эта текстовая строка выводится, когда пользователи отключают в браузере вывод графики, задавая тем самым текстовое описание отсутствующих изображений. Текст также может быть озвучен специальной программой чтения, применяемой пользователями с недостатками зрения, которые иначе не могут видеть или четко различать изображения.
Отметим, что тег <img/> является пустым тегом; он не использует пару из открывающего и закрывающего тегов, так как не охватывает никакой контент. Он только помечает расположение изображения на странице. Он, как линейный тег, должен кодироваться внутри блочного тега, такого, как тег <p>. По умолчанию изображение выравнивается по левому краю страницы.
Изображение JPEG, показанное на рисунке 2.15, должно находиться в том же каталоге, что и страница Web, на которой оно выводится. Изображение помещается на странице в месте расположения тега <img/> с соответствующим кодом. (Если провести указатель мыши над изображением на странице, то появится всплывающая подсказка атрибута alt).
<p><img src="Stonehenge.jpg" alt="Изображение Стоунхенджа"/></p>

Рис. 2.15. Код тега <img/> и вывод в браузере соответствующего изображения
Обратите внимание, что физическое расположение изображения может быть произвольным. На страницу помещается тег <img/>, содержащий адрес URL файла изображения. Когда страница Web загружается в браузер, этот URL используется для определения местоположения файла изображения, который затем передается браузеру отдельно для вывода на странице. Именно поэтому размер файла изображения является важным вопросом. Вывод изображения требует дополнительной передачи данных с сервера Web для каждого изображения, появляющегося на странице. Поэтому слишком большое количество изображений и их большие размеры увеличивают время загрузки страницы Web в окне браузера.
Тег <p>
Для форматирования блока текста как параграфа этот текст ограничивается с помощью тега <p> (paragraph). Общая форма этого тега представлена в листинге 2.2.
<p>текст</p>
Листинг 2.2. Общая форма тега <p> (html, txt)
Между открывающим и закрывающим тегами может находиться любой объем текста. При выводе в браузере вложенный текст содержит только односимвольные пробелы и перед ним и после него следует пустая строка, чтобы отделить от окружающего содержимого страницы.
Результат действия тегов <p> на странице Web можно видеть на показанном ранее рисунке 2.4, который выводит текст в виде четырех отдельных параграфов. Эти теги добавляют в редакторе, как показано ниже.
Компоновка страницы Web
<p>Страница Web начинается с предварительных разделов кода, которые определяют документ XHTML. Также включается заголовок, который появляется в панели заголовка браузера.</p>
<p> Все содержимое, которое появляется в окне браузера, кодируется в разделе тела страницы. Текстовая информация, графические изображения, ссылки и другое содержимое страницы добавляются на страницу и ограничиваются тегами XHTML, чтобы упорядочить и структурировать их представления. </p>
<p>Важно отметить, что содержимое организовано на странице только с помощью тегов XHTML, закодированных в документе. Иначе все содержимое выводится как одна неформатированная строка текста. </p>
Листинг 2.3. Страница Web, форматированная тегами параграфов (html, txt)
Текст теперь легко читается, так как в его информационное содержание внесена некоторая организация. Отметим, что смежные параграфы разделяются одиночными пустыми строками, несмотря на то, что каждый тег <p> порождает пустую строку перед и после параграфа. Браузер объединяет пустую строку, которая следует за параграфом, и пустую строку, которая предшествует следующему параграфу, в одну строку.
(Отметим, что в тексте книги полное кодирование страницы Web может отсутствовать, чтобы сосредоточиться на обсуждаемом коде. Тем не менее, подразумевается, что показанный код окружен предварительными строками страницы до тега <body> и закрывающими тегами </body> и </html>.)
Удаленные ссылки
Если известен адрес URL сайта Web где-нибудь в WWW, можно сделать ссылку на этот сайт. Этот URL обычно имеет следующую форму:
http://имя домена,
где протокол http предшествует местоположению сайта (имя домена). Абсолютная ссылка такого вида ведет на домашнюю страницу этого сайта. Следующий код ссылки, например, используется для перехода на домашнюю страницу www.google.com.
<a href="http://www.google.com">Перейти на Google</a>
Перейти на Google
Листинг 2.33. Код и вид ссылки на внешний сайт Web (html, txt)
Чтобы узнать URL сайта Web, зайдите просто на этот сайт и прочитайте URL, который появится в поле адреса браузера. Скопируйте этот адрес в атрибут href тега <a> и добавьте текст, чтобы создать реагирующую на щелчок текстовую ссылку. Если соединиться с определенной страницей на удаленном сайте, то за именем домена будет следовать путь доступа через структуру каталогов к указанной странице. Например, следующий URL указывает на страницу на сайте directory.google.com, содержащую ссылки на различные бизнес сайты и службы.
<a href="http://directory.google.com/Top/Business/">Business Sites</a>
Business Sites
Листинг 2.34. Код и вид ссылки на внешний сайт Web и структуру каталогов (html, txt)
Эта страница расположена в подкаталоге Business каталога Top на сайте. Адрес URL скопирован из поля адреса браузера при выводе этой страницы.
Упорядоченные списки
Упорядоченный список является последовательностью элементов, перед которыми стоят последовательные числа, выделенной из окружающего текста одиночными пустыми строками. По умолчанию список нумеруется последовательными десятичными числами, начиная с 1 и до последнего элемента списка.
Элементы списка выводятся через один интервал и смещаются от левого края таким же образом, как и неупорядоченный список. Пример упорядоченного списка показан ниже в листинге 2.22.
1. Элемент списка 1 2. Элемент списка 2 3. Элемент списка 3
Листинг 2.22. Вывод упорядоченного списка в браузере (html, txt)
Вывод упорядоченного списка в браузере.
Упорядоченный список создается с помощью контейнерного тега <ol>, который обрамляет элементы списка, идентифицируемые контейнерными тегами <li>. Общая форма кодирования упорядоченного списка показана в листинге 2.23.
<ol> <li>элемент списка </li> <li>элемент списка </li> ... </ol>
Листинг 2.23. Общая форма упорядоченного списка (html, txt)
Например, упорядоченный список, показанный выше в листинге 2.22, задается следующим кодом.
<ol> <li>Элемент списка 1</li> <li>Элемент списка 2</li> <li>Элемент списка 3</li> </ol>
Листинг 2.24. Код упорядоченного списка (html, txt)
Элементы списка выводятся через один интервал и с переносом слов внутри символа нумерации. Элементы списка могут содержать теги <p> или разделяться тегами <br/> для увеличения межстрочного интервала между элементами.
Вложенные неупорядоченные списки
Неупорядоченные списки можно вкладывать друг в друга. Например, маркированный список внутри второго маркированного списка, который входит в третий маркированный список, создается следующим кодом и выводится в браузере, как показано в листинге 2.21. Отметим, что вложенный неупорядоченный список является частью элементов списка своего объемлющего списка. То есть, теги <ul>...</ul> вложенного списка находятся внутри пары тегов <li>...</li> охватывающего списка.<ul> <li>Элемент списка 1</li> <li>Элемент списка 2 <ul> <li>Элемент списка 2a</li> <li>Элемент списка 2b <ul> <li>Элемент списка 2b1</li> <li>Элемент списка 2b2</li> </ul> </li> </ul> </li> <li>Элемент списка 3</li> </ul>
Листинг 2.20. Код вложенных неупорядоченных списков (html, txt) Элемент списка 1 · Элемент списка 2 · Элемент списка 2a · Элемент списка 2b · Элемент списка 2b1 · Элемент списка 2b2 · Элемент списка 3
Листинг 2.21. Вывод в браузере вложенных неупорядоченных списков (html, txt)
Каждый вложенный список еще дальше сдвигается внутрь своего списка-контейнера. Для вложенных списков используются также различные символы маркеров. По умолчанию символ залитого круга помечает самый внешний список, символ окружности помечает следующий вложенный список, а символ залитого квадрата помечает внутренний список. Отметим, что когда списки содержатся внутри других списков, никакие пустые строки не окружают внутренние списки, как это происходит, когда одиночный список появляется в обычном потоке текста на странице.
Вложенные теги <blockquote>
В следующем примере теги <blockquote> используются для смещения трех параграфов, средний из которых смещен еще глубже внутрь своих внешних смещенных параграфов. Вывод браузера показан на рисунке 2.7.
<p>Здесь пять параграфов. Первый параграф форматирован стандартным тегом параграфа и прижат к левому краю страницы.</p>
<blockquote> <p>Второй параграф форматирован с помощью тега blockquote, чтобы сместить его края слева и справа примерно на 40 пикселей от краев страницы. </p>
<blockquote> <p>Этот параграф также заключен в теги blockquote. Он еще дальше смещает границы параграфа, внутри границ, созданных внешним тегом blockquote.</p> </blockquote>
<p>Этот параграф выравнивается как второй параграф, так как он тоже находится внутри внешнего тега blockquote.</p> </blockquote>
<p>Пятый параграф кодируется как первый. Он помещен внутри стандартного тега параграфа и прижат к левому краю.</p>
Листинг 2.7. Блоки текста, форматированные с помощью вложенных тегов <blockquote> (html, txt)
Рис. 2.7. Параграфы, форматированные с помощью вложенных тегов <blockquote>
В этом примере два тега <blockquote> вложены друг в друга, то есть тег <blockquote> появляется внутри тега <blockquote>. Внешний тег <blockquote> охватывает и смещает три своих вложенных текстовых блока примерно на 40 пикселей от левого и правого края страницы. Внутренний тег <blockquote> смещает свой вложенный текст еще примерно на 40 пикселей от краев, определенных внешним тегом. Любые дополнительные вложенные теги еще в большей степени смещают свой вложенный текст от предыдущих границ.
При вложении тегов <blockquote> друг в друга проверяйте, что открывающий и закрывающий теги правильно согласованы - что внутренние теги полностью закрыты внутри своих следующих внешних ближайших охватывающих тегов.
Как и в случае тегов <p>, смежные теги <blockquote> заменяют предшествующую и последующую пустые строки одной пустой строкой.
Тег <blockquote> является одним из способов создания отступов для параграфов текста. В дальнейшем мы узнаем о методах таблиц стилей для удвоения эффекта тега и для получения большего контроля над промежутком отступа.
Вложенные упорядоченные списки
Упорядоченные списки можно вкладывать друг в друга, при этом подчиненные списки смещаются относительно следующего охватывающего списка. Все вложенные упорядоченные списки используют одну и ту же десятичную систему нумерации, начинающуюся с десятичной 1. Следующий код, например, создает нумерованные списки, показанные в листинге 2.26.
<ol> <li>Элемент списка 1</li> <li>Элемент списка 2 <ol> <li>Элемент списка 2.1</li> <li>Элемент списка 2.2</li> </ol> </li> <li>Элемент списка 3</li> </ol>
Листинг 2.25. Код вложенных упорядоченных списков (html, txt) 1. Элемент списка 1 2. Элемент списка 2 1. Элемент списка 2.1 2. Элемент списка 2.2 3. Элемент списка 3
Листинг 2.26. Вывод в браузере вложенных упорядоченных списков (html, txt)
Отметим, что когда упорядоченные списки содержатся внутри других упорядоченных списков, никакие пустые строки не отделяют внутренние списки, как это происходит, когда список появляется внутри обычного потока текста страницы.
Вывод изображений
Кроме представления текстового содержимого, на страницах Web можно выводить графические изображения. В дальнейшем эта тема будет рассмотрена подробнее. Здесь вводятся базовые методы вывода изображений на странице.
Вывод в редакторе и браузере
Вспомните, что создание страницы Web начинается со стандартной настройки документа, которая задает его общую структуру. Шаблон такой страницы показан ниже.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"> <head> <title>здесь находится заголовок страницы </title> </head> <body> . здесь находится содержимое страницы . </body> </html>
Листинг 2.1. Шаблон страницы Web (html, txt)
Каждая создаваемая страница начинается с этого кода. Необходимо написать подходящее название для страницы в теге <title>. Этот текст будет выводиться в панели заголовка браузера при открытии страницы. Затем внутрь тега <body> вносится информационное содержимое. В окне браузера выводится только та информация, которая присутствует в теле документа. Именно внутри тега <body> помещают текст и графические изображения вместе с тегами XHTML для их упорядочивания и организации.
Важно понимать, что форматирование страниц Web происходит только за счет тегов XHTML. Чтобы подчеркнуть этот момент, рассмотрим заголовок и три параграфа, показанные в редакторе Notepad на рисунке 2.1. Задача состоит в том, чтобы вывести эту информацию в браузере в такой же общей форме.
Рис. 2.1. Документ Web, представленный в редакторе Notepad
Заголовок, имеющийся вверху документа, и все параграфы отделяются друг от друга пустыми строками. Надо постараться ввести информацию в редакторе в том же виде, как она представлена в браузере. Необходимо следить за тем, чтобы сам вывод в редакторе был аккуратен и легко читаем. Однако форматирование редактора мало связано с тем, как введенная информация выводится на странице Web.
Если этот документ сохранить как файл XHTML, а затем открыть в браузере, то он будет выведен, как показано на рисунке 2.2.
Рис. 2.2. Вывод неформатированной страницы Web в браузере
Ее представление существенно отличается от ее вывода в редакторе. Причина, конечно, в том, что в документе отсутствуют теги XHTML, которые руководят браузером при размещении текста на странице. Поэтому браузер воспринимает всю информацию как одну непрерывную строку текста. Все пробелы и переносы строк, присутствующие в редакторе, сокращаются до одиночных пробелов, разделяющих слова; в результате на странице получаем единственный блок текста.
Заголовки
Появляющийся на странице Web текст выводится используемым по умолчанию типом шрифта и размером, если не определено иное. Большинство браузеров выводят текст шрифтом или семейством шрифтов Times New Roman, размером примерно 12 пунктов. Чтобы внести на страницу визуальное разнообразие, для различных разделов документа часто выбирают различные типы и размеры шрифтов. Эта тема будет подробнее рассмотрена в дальнейшем, скажем лишь, что существуют простые способы изменения размера шрифта, позволяющие добавлять на страницу заголовки различного уровня.
Тег <hn> (heading) является блочным тегом, которых ограничивает строку текста для вывода одним из шести стилей заголовка. Его общая форма показана В листинге 2.11.
<hn>Текст заголовка</hn>
Листинг 2.11. Общая форма тега <hn> (html, txt)
Число n в теге может изменяться от 1 (самый крупный) до 6 (самый мелкий). Эти шесть уровней заголовков приведены в следующем примере и выводятся в браузере, как показано на рисунке 2.10. Стандартный параграф выводится для сравнения.
<h1>Заголовок уровня 1</h1> <h2>Заголовок уровня 2</h2> <h3>Заголовок уровня 3</h3> <h4>Заголовок уровня 4</h4> <h5>Заголовок уровня 5</h5> <h6>Заголовок уровня 6</h6>
<p>Обычный текстовый параграф.</p>
Листинг 2.12. Создание заголовков с помощью тега <hn> (html, txt)
Рис. 2.10. Вывод в браузере тегов <hn>
Заголовки выводятся полужирными символами используемого по умолчанию шрифта, на отдельной строке с предшествующей и последующей одиночной пустой строкой. Таким образом, тег <hn> нельзя использовать для изменения размера текста в середине строки или середине параграфа, так как он создает перенос строки перед и после своего вложенного текста. Он применяется для блочного автономного текста, наиболее часто - в качестве заголовков содержимого для идентификации и выделения разделов страницы Web.
